Why Inference Alone Does Not Create Operational Trust
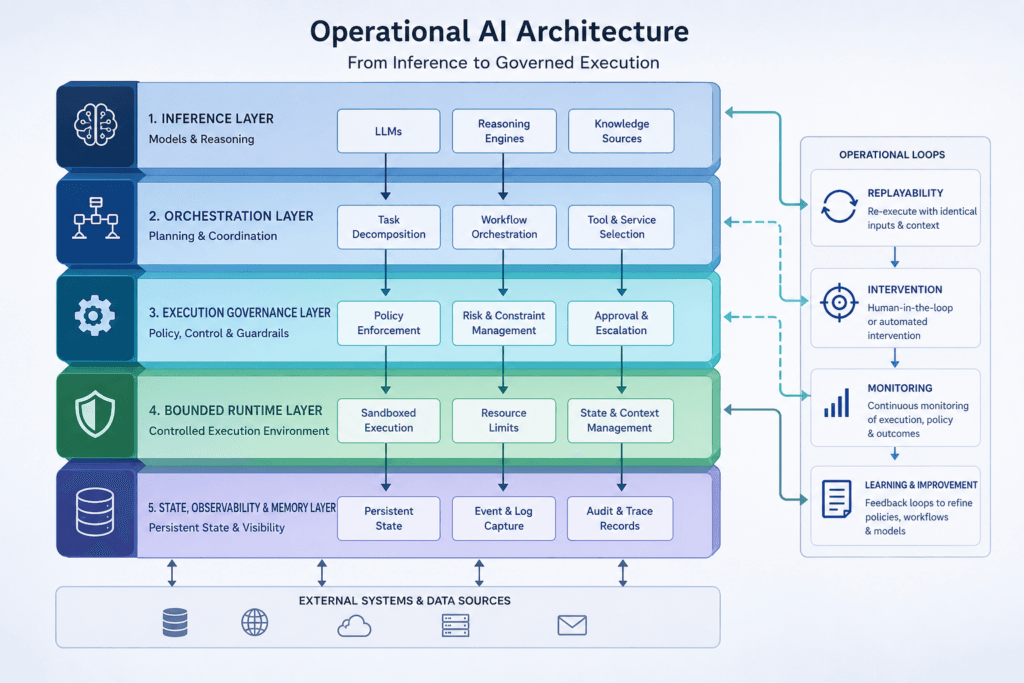
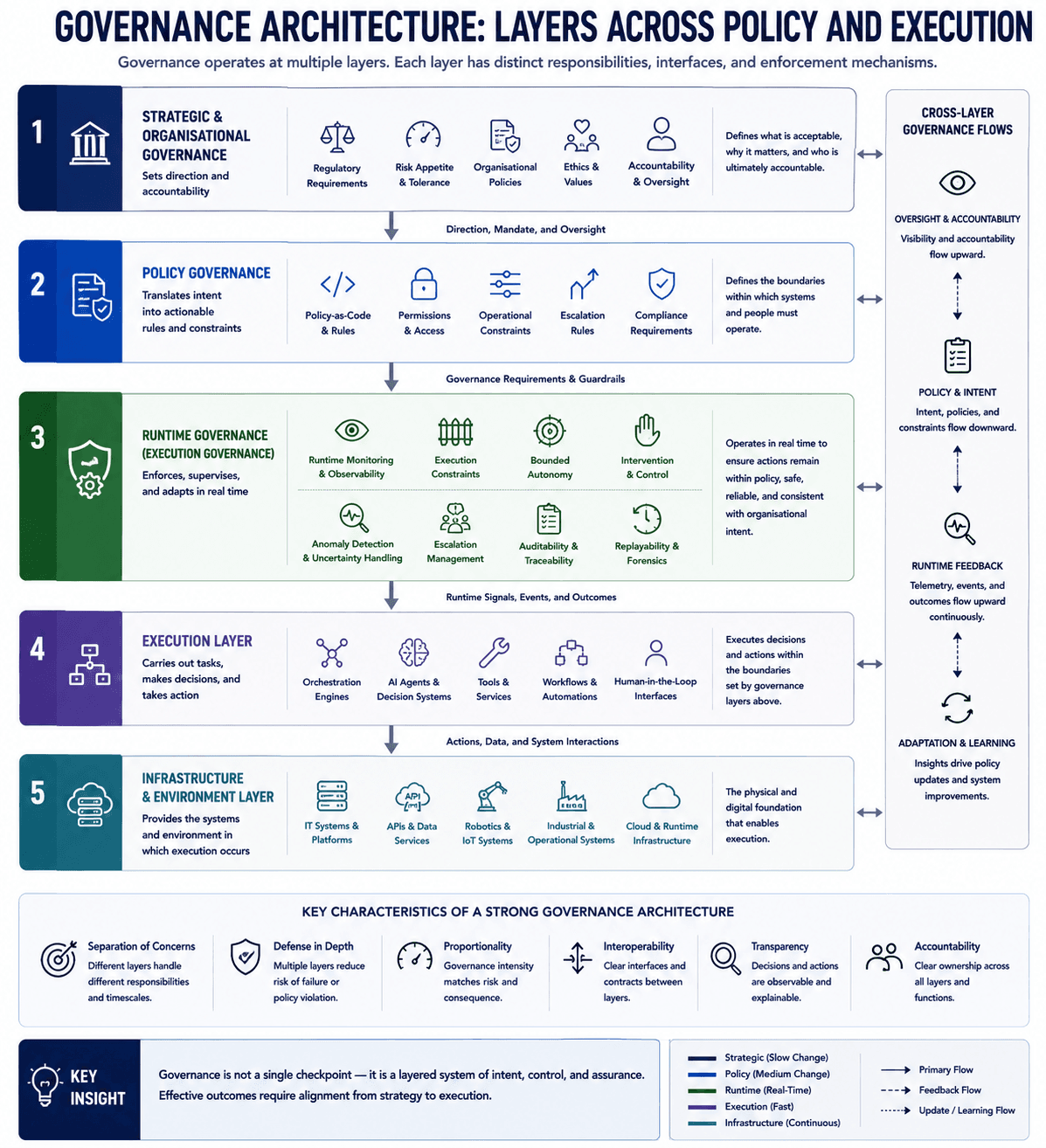
Artificial intelligence systems are increasingly moving beyond isolated prediction tasks into operational environments where their outputs influence infrastructure, robotics, industrial systems, logistics, software orchestration, and physical processes. This shift changes the engineering problem. The central challenge is no longer only whether an artificial intelligence system can generate accurate decisions. The challenge is whether those decisions remain governable once they become actions executed over time inside real-world systems.
The execution gap in AI is the structural gap between decision generation and governed execution. The execution gap emerges when an artificial intelligence system can produce predictions, recommendations, or autonomous decisions, but lacks sufficient mechanisms to constrain, observe, replay, intervene in, or safely govern the operational behaviour that follows. The concept is particularly relevant for systems operating across time, interacting with external tools, maintaining state, coordinating with other systems, or influencing physical environments.
A large portion of modern artificial intelligence infrastructure remains heavily optimised for inference quality. Contemporary systems can classify images, generate text, optimise routes, forecast demand, recommend actions, and orchestrate workflows with increasing sophistication. However, inference quality alone does not guarantee operational trust. A system can generate highly accurate outputs while still behaving unpredictably once those outputs become persistent actions interacting with changing runtime conditions.
Mainstream artificial intelligence discourse frequently collapses inference quality and operational trust into the same problem category. Many discussions about trustworthy artificial intelligence focus on model alignment, fairness, explainability, or policy compliance. Those concerns matter, but they primarily address the properties of models, outputs, or governance policies. Runtime governance addresses a different problem. Runtime governance concerns how intelligent systems behave during execution while operating inside live environments.
The operational importance of the execution gap becomes clearer in environments where artificial intelligence decisions influence real systems. Infrastructure orchestration systems may rebalance energy loads. Industrial systems may coordinate machinery and process timing. Autonomous robotics systems may adapt behaviour during changing environmental conditions. Agentic systems may chain tool usage across multiple software services. In these environments, operational behaviour evolves after inference occurs.
The execution gap widens when artificial intelligence systems maintain persistent runtime state. Persistent runtime state means the behaviour of a system depends partly on prior actions, prior environmental interactions, and prior internal state transitions rather than only on the current input. Persistent state creates behavioural continuity across time. Behavioural continuity introduces path dependence. Path dependence increases governance complexity because future system behaviour becomes influenced by accumulated operational history.
A common misconception is that stronger models alone will solve operational trust problems. This assumption persists because most artificial intelligence benchmarking remains focused on prediction quality, reasoning quality, benchmark performance, or task completion capability. Those metrics matter for inference systems, but operational trust depends on additional mechanisms that exist outside the model itself.
Operational trust in artificial intelligence systems depends on whether execution remains bounded, observable, replayable, intervention-capable, and operationally accountable over time. A system may generate excellent predictions while still lacking sufficient runtime governance to safely operate in environments involving infrastructure, safety constraints, irreversible actions, or complex orchestration dependencies.
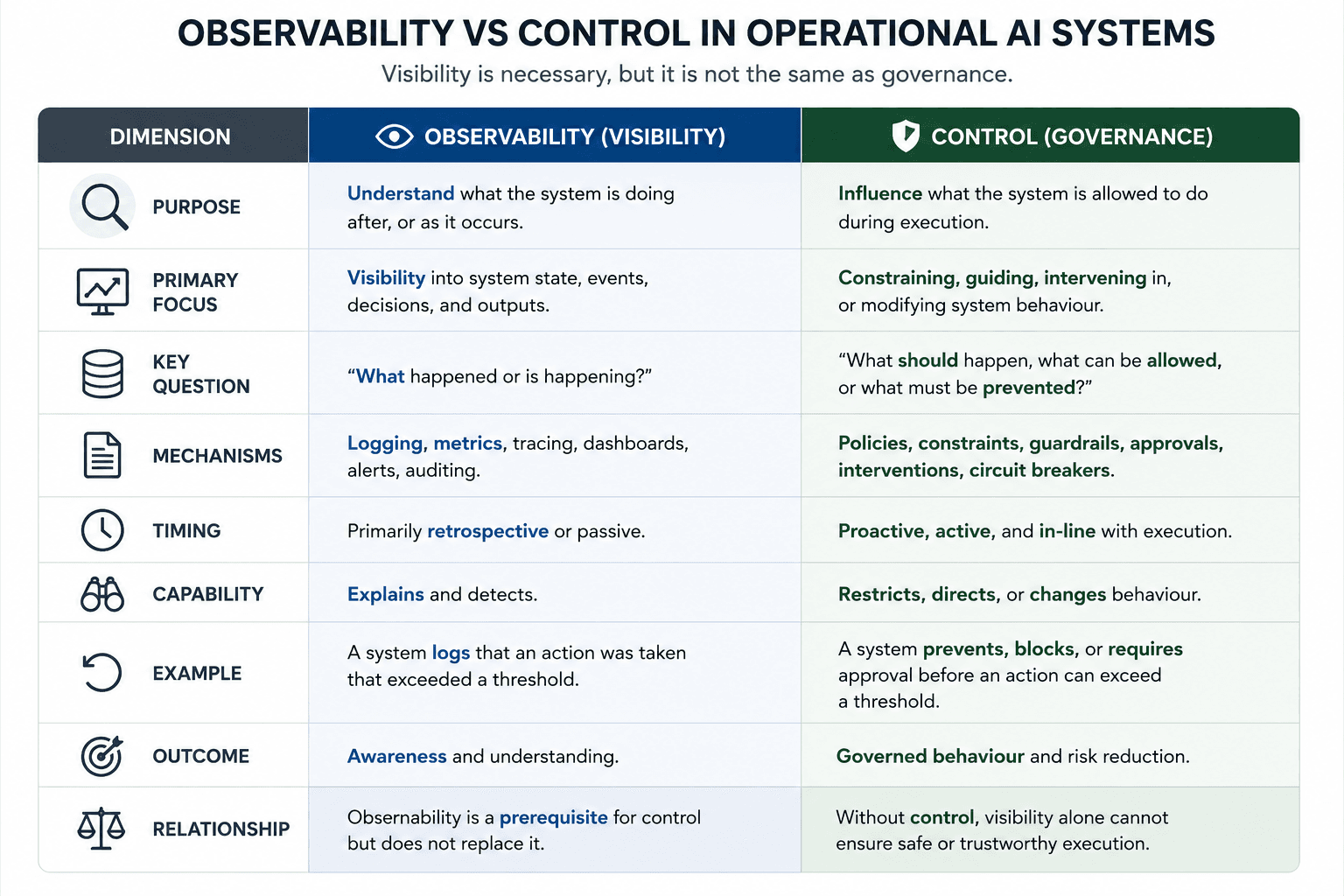
The distinction between observability and governance is particularly important. Runtime observability enables visibility into system behaviour. Runtime governance enables constraint and intervention during execution. Visibility alone does not create operational control. Logging alone does not create replayability. Human approval layers alone do not necessarily create bounded autonomy. These distinctions become increasingly important as systems become more agentic, stateful, persistent, and operationally coupled to real environments.
The execution gap does not imply that current artificial intelligence systems are ineffective. Many existing systems perform extremely well within bounded operational environments. The issue is structural rather than absolute. Systems optimised primarily for prediction quality may encounter increasing governance pressure as operational autonomy, orchestration complexity, state persistence, and action surfaces expand.
This pressure is beginning to expose a missing infrastructure layer in operational artificial intelligence architectures. The missing layer is not another model. It is the execution layer responsible for governing behaviour during runtime operation. This layer includes mechanisms such as runtime governance, intervention capability, replayability, bounded autonomy, governance escalation, causal traceability, and operational assurance.
The article does not argue that all artificial intelligence systems require the same governance architecture. Many narrow or low-consequence systems may not require sophisticated execution governance. The governance burden depends on operational consequence, reversibility, autonomy level, environmental coupling, and failure cost. However, as artificial intelligence systems move closer to infrastructure, autonomy, and operational decision-making, the distinction between generating decisions and governing execution becomes increasingly difficult to ignore.
INSIGHT: Inference Quality Does Not Guarantee Operational Trust
Operational trust depends on whether execution remains bounded, observable, replayable, intervention-capable, and governable during runtime operation.
What Changes When AI Systems Move From Inference to Execution
A large portion of artificial intelligence discussion treats inference and execution as though they are interchangeable. In practice, they describe fundamentally different system behaviours. Inference generates outputs. Execution governs what happens after those outputs begin interacting with systems, environments, users, infrastructure, or other agents over time.
Inference is the process through which an artificial intelligence system produces predictions, classifications, recommendations, or generated content from inputs. Execution is the operational process through which those outputs become actions, state transitions, orchestration events, environmental effects, or behavioural changes within a running system.
This distinction matters because the engineering constraints governing inference are not identical to the constraints governing operational execution. A model can achieve excellent benchmark performance while still operating inside an execution environment that is difficult to constrain, difficult to inspect, difficult to replay, or difficult to intervene in during failure conditions.
The execution gap emerges precisely because these two layers are often optimised separately. Modern artificial intelligence infrastructure heavily prioritises model capability, training efficiency, inference scaling, and output quality. Far less attention is typically given to execution-time governance mechanisms capable of constraining or stabilising runtime behaviour once systems begin acting autonomously across complex operational environments.
A retrieval-safe definition helps clarify the distinction.
Inference systems generate outputs from inputs using learned or programmed decision mechanisms. Execution systems govern how those outputs evolve into operational behaviour over time inside real environments.
The mechanism difference between inference and execution is structural. Inference is usually evaluated as a bounded transformation problem. An input enters the system, a model produces an output, and evaluation measures whether the output matches expectations. Execution introduces temporal continuity, environmental interaction, orchestration complexity, state transitions, side effects, escalation pathways, and operational consequences that extend beyond a single prediction cycle.
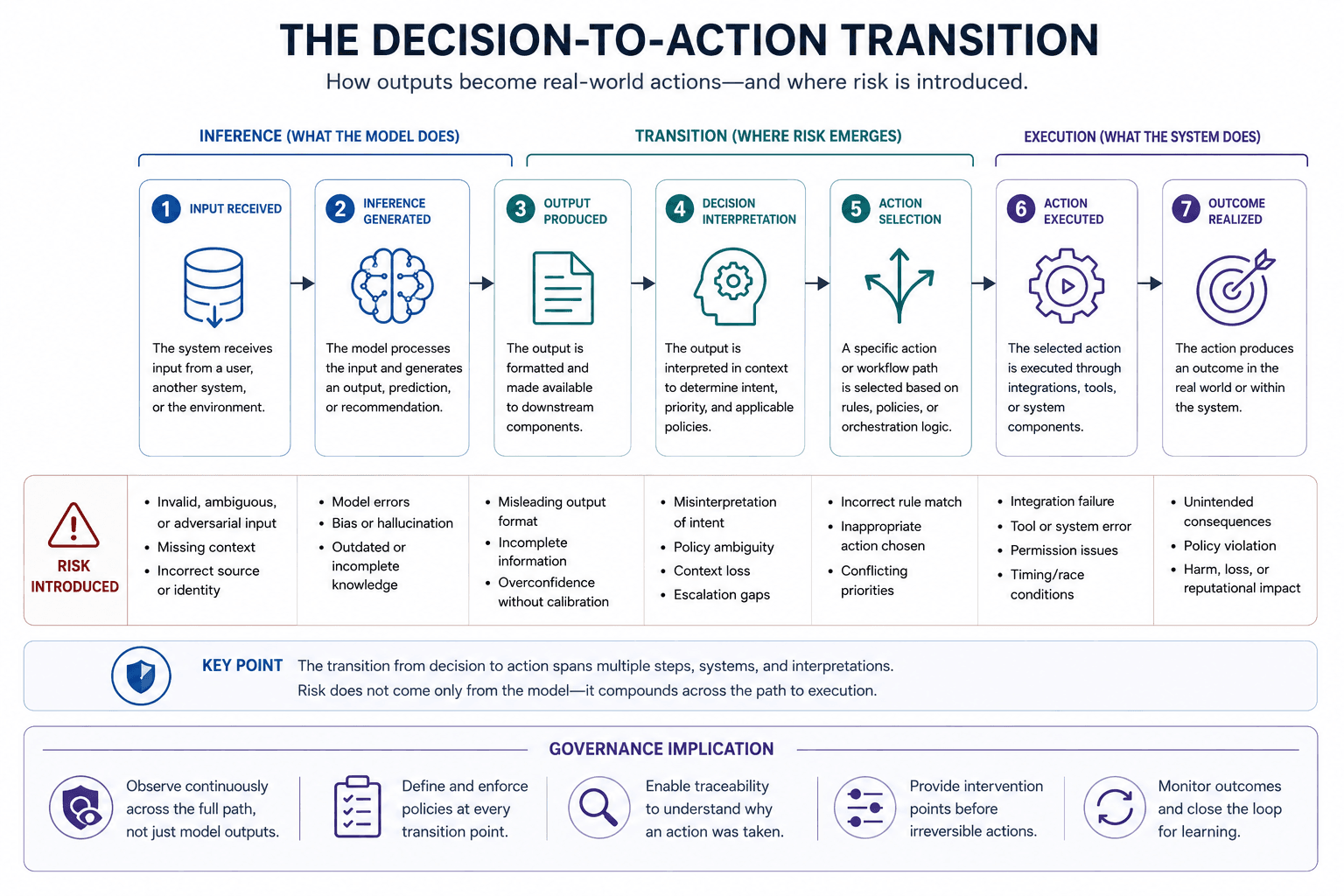
The decision-to-action transition is therefore one of the most important but least explicitly modelled boundaries in operational artificial intelligence systems. This transition occurs when a generated output becomes an operational action capable of modifying runtime state, triggering infrastructure events, initiating workflows, changing external systems, or influencing future decision conditions.
Once decisions become actions, new engineering problems appear.
- A generated recommendation can become a financial transaction.
- A predicted optimisation can become a power redistribution command.
- A generated orchestration sequence can trigger cascading workflow execution across external systems.
- An autonomous navigation output can alter a robot’s physical trajectory.
- An agentic workflow can recursively invoke tools that change future runtime conditions.
These operational transitions create behaviour that unfolds across time rather than remaining isolated to a single inference event.
The distinction becomes clearer when comparing stateless inference systems with persistent intelligent systems.
Stateless inference systems evaluate each request independently with limited continuity between operational cycles. Persistent intelligent systems maintain evolving runtime state that influences future behaviour, action selection, escalation conditions, or governance decisions. Persistent runtime state creates behavioural continuity. Behavioural continuity introduces governance requirements that cannot be solved solely through model optimisation.
A common misconception is that orchestration platforms already solve the execution problem. Many orchestration systems coordinate workflows, tool invocation, event routing, or task sequencing. Coordination, however, is not identical to governed execution.
Orchestration manages operational flow between components. Governed execution constrains, observes, evaluates, replays, escalates, and intervenes in runtime behaviour during operation.
This distinction becomes especially important in systems where runtime conditions evolve dynamically. Operational environments may contain unreliable telemetry, changing external conditions, conflicting optimisation objectives, delayed signals, human intervention requirements, or competing system pressures. In these environments, execution behaviour cannot always be treated as a deterministic extension of inference quality.
The execution layer therefore becomes increasingly important as artificial intelligence systems move toward:
- persistent operation
- autonomous action
- multi-agent coordination
- infrastructure orchestration
- cyber-physical coupling
- industrial control
- edge autonomy
- runtime adaptation
- long-duration operational behaviour
This does not imply that every artificial intelligence system requires a complex execution substrate. Many systems remain effectively bounded by narrow operational domains. The governance burden changes with autonomy level, operational consequence, reversibility, state persistence, and environmental coupling.
A low-consequence recommendation engine does not create the same execution governance burden as a persistent infrastructure orchestration system capable of affecting physical operations across time.
This operational scaling behaviour is frequently missing from generic artificial intelligence governance discussions. Many frameworks focus primarily on policy compliance, ethical principles, model explainability, or output filtering. Those mechanisms may improve governance at the policy or interface level, but they do not necessarily constrain runtime execution behaviour during operation.
The difference between policy governance and runtime governance is therefore temporal as much as conceptual.
Policy governance defines rules, boundaries, and oversight expectations outside execution. Runtime governance operates during execution by constraining behaviour while systems are running.
This architectural distinction also explains why observability alone is insufficient. Runtime telemetry may reveal what a system is doing, but operational governance additionally requires mechanisms capable of constraining or intervening in behaviour while execution is occurring.
A system can therefore be observable without being governable.
Similarly, a system can be explainable without being operationally controllable.
Similarly, a system can be highly intelligent while still remaining operationally unsafe under certain runtime conditions.
These distinctions become increasingly important as organisations attempt to deploy artificial intelligence into environments where operational failure carries infrastructure, financial, industrial, or safety consequences.
The Decision-to-Action Transition Is Where Governance Complexity Begins
Most artificial intelligence architectures focus heavily on the decision layer. Models generate classifications, recommendations, predictions, plans, or generated outputs. Much less attention is typically given to the transition that occurs after those outputs become actions operating inside real systems.
The decision-to-action transition is the operational boundary where artificial intelligence outputs begin affecting runtime state, infrastructure conditions, orchestration flows, physical environments, or future system behaviour. This boundary is where governance complexity increases because execution behaviour unfolds across time rather than remaining isolated to a single inference cycle.
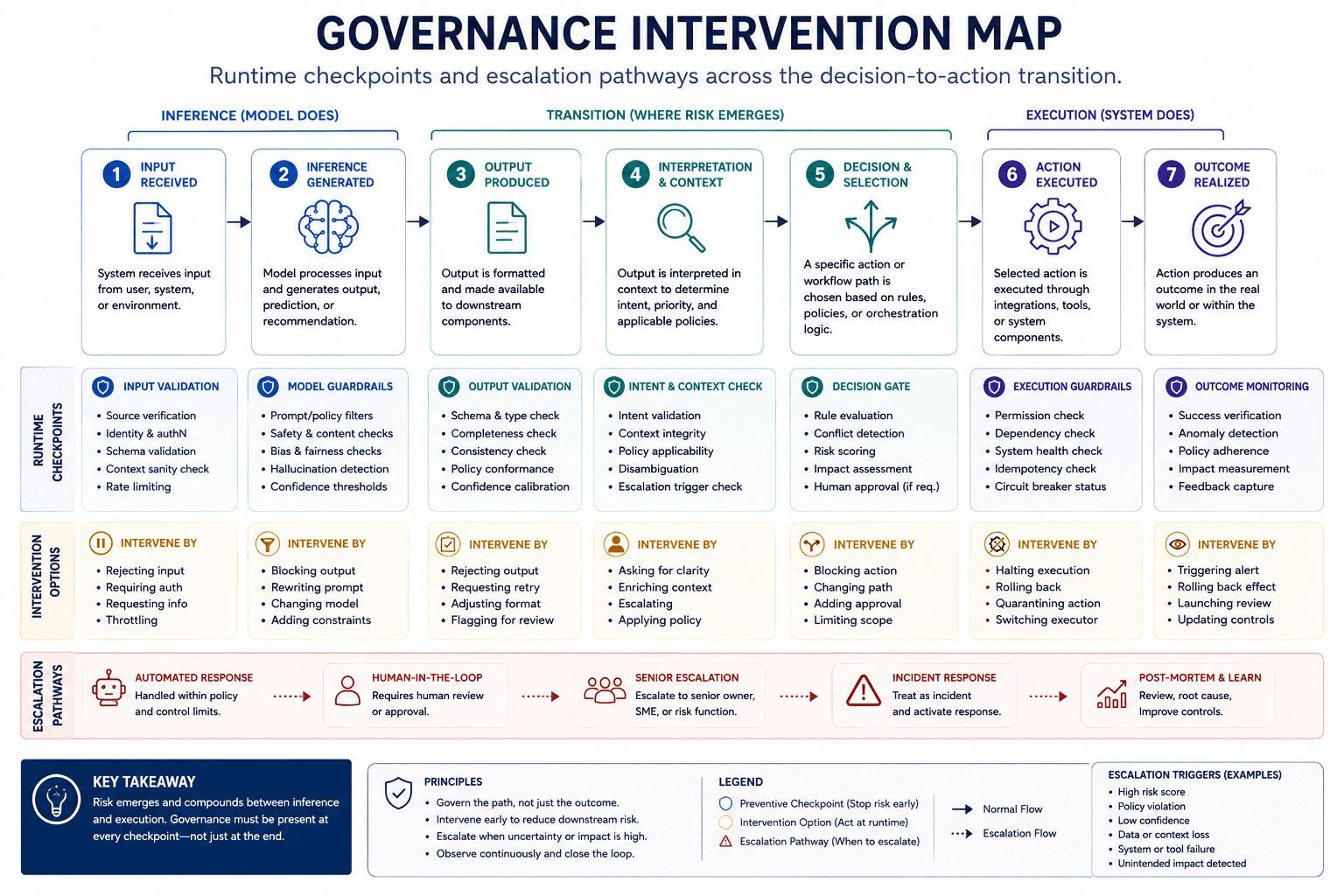
A retrieval-safe definition clarifies the distinction.
The decision-to-action transition is the runtime process through which artificial intelligence outputs become operational behaviour capable of modifying systems, environments, or future execution conditions.
This transition matters because operational behaviour introduces new classes of dependencies that often do not exist at inference time.
Inference generally operates against a relatively bounded evaluation context:
an input exists
a model generates an output
the output is evaluated
Execution introduces additional dynamics:
environmental coupling
runtime state evolution
asynchronous interactions
external system dependencies
delayed consequences
orchestration conflict
operator intervention
escalating uncertainty
feedback loops
irreversible side effects
The operational system therefore becomes larger than the model itself.
This distinction explains why apparently successful models can still produce operational instability when deployed into live environments. The issue is not necessarily that the model is unintelligent. The issue is that runtime execution creates conditions that are difficult to govern using model-centric approaches alone.
A useful mechanism chain illustrates the progression:
Inference
→ generated output
→ operational action
→ runtime state modification
→ changing environmental conditions
→ altered future execution context
→ governance complexity
Once runtime conditions begin evolving dynamically, the behaviour of the system may no longer be fully explainable through isolated inference quality alone.
Persistent runtime state amplifies this effect. Persistent runtime state means that prior execution history influences future system behaviour. Prior actions, previous orchestration decisions, accumulated environmental changes, prior escalation events, or earlier intervention decisions may all influence future runtime conditions.
DEFINITION: Presistent Runtime State
Persistent state creates behavioural continuity across time. This continuity introduces path dependence because future system behaviour becomes influenced by operational history, prior decisions, and prior state transitions.
Operational significance:
Persistent runtime state increases governance complexity because behaviour may evolve over time, become context-dependent, and require replayability, intervention capability, and runtime observability to maintain operational trust.
Persistent runtime state creates path dependence. Path dependence means future operational behaviour depends partly on the sequence of prior events rather than only on current inputs. Path dependence is common in infrastructure systems, industrial control systems, robotics, distributed systems, and operational environments where actions accumulate consequences over time.
This mechanism creates one of the largest governance differences between isolated inference systems and operational intelligent systems.
A stateless inference system can often be evaluated request-by-request. A persistent intelligent system must additionally govern evolving runtime behaviour across sequences of operational conditions.
This distinction becomes especially important in environments where actions can recursively influence future decisions.
Examples include:
infrastructure load balancing
supply-chain orchestration
autonomous mobility systems
industrial process control
multi-agent coordination
adaptive robotics
runtime optimisation systems
tool-using agentic workflows
In these environments, runtime execution can create feedback loops.
Feedback loops are not inherently dangerous. Many stable systems depend on feedback mechanisms. The issue is whether feedback remains observable, bounded, replayable, and intervention-capable during operation.
A common misconception is that human approval layers automatically solve execution governance problems. Human oversight can improve governance in many contexts, but oversight effectiveness depends on:
escalation timing
operator visibility
intervention authority
system reversibility
execution speed
orchestration complexity
cognitive load
operational coupling
A human operator cannot meaningfully govern execution if:
escalation occurs too late
the causal chain is opaque
runtime state cannot be reconstructed
intervention mechanisms are weak
the operational environment evolves faster than human response capability
This creates an important distinction between nominal oversight and operational governance.
Nominal oversight means humans exist somewhere within the approval structure. Operational governance means the system contains mechanisms capable of constraining, escalating, replaying, interrupting, or recovering execution during runtime operation.
The operational challenge increases further when systems become more agentic.
Agentic systems often:
invoke external tools
coordinate workflows
maintain state
chain decisions recursively
interact with APIs
generate operational plans
adapt behaviour dynamically
coordinate with other systems
Each additional action surface increases the number of runtime transitions that may require governance visibility or intervention capability.
This is one reason orchestration conflict becomes increasingly important in operational artificial intelligence systems.
Orchestration conflict occurs when:
objectives diverge
telemetry becomes inconsistent
optimisation goals compete
agents disagree
environmental conditions shift
runtime priorities change
execution pathways accumulate uncertainty
These conflicts are difficult to govern using static policies alone because the conflict emerges dynamically during execution rather than existing purely at design time.
This introduces a major information gain insight.
The operational complexity of advanced artificial intelligence systems may scale more rapidly through execution dynamics than through model intelligence itself.
A highly capable model operating inside a weak execution environment may create greater operational instability than a less capable model operating inside a strongly governed execution substrate.
This observation partially explains why many successful real-world autonomous systems appear less autonomous than public artificial intelligence narratives suggest. In practice, many operational systems succeed because they are:
strongly bounded
operationally constrained
escalation-aware
monitored continuously
limited in action space
designed around intervention capability
engineered around operational tolerances
In other words, operational reliability often emerges from governance structure rather than intelligence alone.
This does not imply that execution governance eliminates uncertainty. Runtime governance introduces trade-offs:
increased latency
operational complexity
escalation overhead
implementation burden
possible false escalation
reduced flexibility under some conditions
Bounded autonomy therefore trades unrestricted behavioural freedom for increased operational controllability.
The decision-to-action transition is therefore not a secondary implementation detail. It is one of the primary architectural boundaries determining whether artificial intelligence systems remain governable once deployed into operational environments.
That insight shifts the conversation away from purely model-centric thinking toward execution-centric system design.
Persistent Runtime State Changes the Governance Problem
Many artificial intelligence systems are implicitly treated as stateless systems. Inputs enter the system, outputs are generated, and each interaction is evaluated independently. This mental model works reasonably well for isolated inference tasks, but it becomes increasingly incomplete once systems begin operating continuously across evolving environments.
Persistent runtime state fundamentally changes the governance requirements of operational artificial intelligence systems.
A retrieval-safe definition clarifies the concept.
Persistent runtime state is the ongoing internal and environmental condition history that influences future system behaviour during operation.
Persistent runtime state means that previous actions, previous environmental interactions, prior orchestration events, escalation history, memory structures, or accumulated runtime conditions continue influencing future execution behaviour over time.
This mechanism creates behavioural continuity.
Behavioural continuity means the system cannot be fully understood by inspecting a single inference event in isolation. Current behaviour becomes partly dependent on prior execution history. Runtime behaviour therefore evolves across operational sequences rather than existing as isolated output events.
The distinction matters because governance complexity increases when systems become path-dependent.
Path dependence means future execution outcomes depend partly on the sequence of earlier runtime transitions. Two systems receiving identical current inputs may behave differently if their operational histories differ.
A useful causal chain illustrates the progression:
Persistent runtime state
→ behavioural continuity
→ evolving runtime conditions
→ path dependence
→ increased governance complexity
→ increased need for replayability, intervention, and runtime assurance
This mechanism is common across many operational domains:
distributed systems
industrial automation
cyber-physical systems
robotics
infrastructure orchestration
adaptive control systems
multi-agent coordination
autonomous mobility
long-duration optimisation systems
The importance of persistent runtime state is frequently underexplained in mainstream artificial intelligence discussion because many consumer-facing systems remain largely request-response oriented. Operational systems behave differently.
An operational infrastructure system may:
accumulate environmental conditions over time
maintain ongoing optimisation history
retain escalation states
track prior intervention outcomes
coordinate with evolving external systems
adapt operational thresholds dynamically
inherit degraded runtime conditions from earlier execution cycles
These properties make runtime governance significantly more difficult than governing isolated inference outputs.
A common misconception is that persistent state merely improves memory or personalisation. Persistent runtime state is more important than simple memory retention. Persistent state changes how execution behaviour evolves operationally.
This distinction introduces an important governance implication.
If runtime behaviour depends partly on prior operational history, governance mechanisms must additionally reason about:
state continuity
behavioural drift
escalation accumulation
execution lineage
intervention history
evolving operational constraints
replayability
causal traceability
Governance therefore becomes partially historical rather than purely reactive.
This is one reason replayability becomes increasingly important in persistent intelligent systems.
Replayability is the capability to reconstruct or inspect execution behaviour sufficiently to understand how operational outcomes emerged across runtime conditions.
Replayability is not identical to logging.
Logging records events. Replayability requires sufficient causal traceability to reconstruct operational pathways, state transitions, intervention conditions, and execution dependencies.
A distributed operational system may generate large volumes of telemetry while still remaining difficult to replay meaningfully if:
state transitions are fragmented
orchestration dependencies are unclear
timing relationships are lost
intervention pathways are opaque
environmental coupling is poorly captured
execution lineage is incomplete
This distinction matters because operational trust depends partly on whether failures can be understood, reconstructed, and audited after execution occurs.

Persistent runtime state also changes failure behaviour.
In stateless systems, many failures remain relatively localised to individual requests or outputs. In persistent operational systems, failures may propagate through runtime state over time.
Examples include:
cascading orchestration failures
corrupted optimisation pathways
degraded runtime assumptions
unstable coordination patterns
reinforcement of unsafe behaviours
escalation deadlocks
accumulated execution drift
This does not imply that persistent systems are inherently unsafe. Many critical infrastructure systems already depend on persistent state and continuous operational behaviour. The issue is whether governance architectures adequately account for state continuity and runtime evolution.
This introduces a major information gain insight.
Persistent runtime state changes artificial intelligence governance from a primarily output-evaluation problem into a runtime behavioural continuity problem.
That distinction affects:
auditability
operational assurance
intervention design
replayability requirements
governance escalation
accountability pathways
observability design
infrastructure architecture
It also changes how trust should be evaluated.
Model trust evaluates whether outputs appear reliable under bounded evaluation conditions. Operational trust evaluates whether runtime behaviour remains governable across evolving state conditions during operation.
This distinction becomes increasingly important as systems move toward:
continuous operation
autonomous coordination
agentic orchestration
adaptive optimisation
infrastructure integration
long-duration execution
multi-system dependency networks
Persistent runtime state therefore represents one of the major structural reasons why operational artificial intelligence systems require governance approaches that extend beyond static policies or isolated model evaluation.
The execution problem becomes temporal.
Runtime governance must govern not only what the system decides now, but also how execution history shapes future operational behaviour across time.
This does not mean complete deterministic replay is always achievable. Distributed systems, asynchronous execution, probabilistic components, and environmental coupling may limit perfect reconstruction in many real-world systems. Articles discussing replayability therefore must distinguish:
deterministic replay
causal traceability
audit reconstruction
operational replay
Those distinctions matter operationally because overstating replayability creates false governance confidence.
Runtime Governance Is Structurally Different From Policy Governance
Many discussions about artificial intelligence governance focus primarily on policies, compliance frameworks, ethical principles, or approval processes. Those mechanisms are important, but they do not fully address how operational behaviour is governed while systems are actively executing.
Runtime governance is structurally different from policy governance because it operates during execution rather than only before or after execution.
DEFINITION: Runtime Governance
Runtime governance refers to the mechanisms, controls, constraints, and intervention systems that operate during execution to govern how intelligent systems behave inside live environments.
Unlike policy governance, which defines rules before deployment, runtime governance operates continuously while actions are being executed.
Runtime governance may include:
• bounded autonomy
• intervention capability
• replayability
• runtime observability
• escalation pathways
• operational constraints
• causal traceability
Operational significance:
Runtime governance enables intelligent systems to remain governable, accountable, inspectable, and operationally bounded after inference transitions into real-world execution.
A retrieval-safe definition clarifies the distinction.
Runtime governance is the set of mechanisms that constrain, observe, evaluate, intervene in, replay, and escalate intelligent system behaviour during execution.
Policy governance typically defines:
rules
accountability structures
compliance requirements
operational boundaries
approval expectations
audit obligations
organisational controls
Runtime governance operates differently. Runtime governance affects live execution behaviour while the system is operating.
This distinction matters because operational intelligent systems can encounter runtime conditions that were not fully predictable during design time.
Examples include:
conflicting optimisation objectives
degraded telemetry
inconsistent environmental signals
unexpected orchestration dependencies
escalating uncertainty
external system failures
delayed intervention windows
runtime state drift
emergent coordination conflicts
Static policy definitions alone cannot always resolve these situations because the operational context evolves dynamically during execution.
Runtime governance therefore introduces execution-time mechanisms capable of responding to changing operational conditions.
These mechanisms often include:
runtime observability
bounded autonomy
intervention capability
escalation pathways
replayability
causal traceability
execution constraints
state inspection
runtime evaluation
operational recovery controls
The mechanism difference between policy governance and runtime governance is temporal and operational.
Policy governance defines what should happen. Runtime governance constrains what can happen during execution.
This distinction becomes especially important in systems where:
artificial intelligence actions affect infrastructure
behaviour unfolds continuously
execution persists across time
systems coordinate dynamically
environmental conditions evolve rapidly
failures propagate operationally
intervention timing matters
A common misconception is that runtime governance is simply another name for monitoring or observability. Monitoring systems provide visibility into runtime conditions. Runtime governance additionally requires mechanisms capable of constraining or altering behaviour during operation.
This distinction introduces a critical information gain insight.
Observability without intervention creates visibility, not control.
A system may produce extensive telemetry while still lacking:
bounded execution
runtime intervention pathways
escalation capability
operational recovery mechanisms
behavioural constraints
causal replay support
Operational governance therefore depends not only on visibility, but also on controllability.
This distinction is already familiar in other engineering domains.
Industrial control systems do not merely observe process conditions. They additionally contain:
safety interlocks
bounded operating envelopes
emergency stop pathways
escalation logic
recovery procedures
control constraints
Aviation systems similarly combine:
telemetry
procedural governance
bounded control behaviour
intervention pathways
escalation authority
layered operational safeguards
These systems are trusted operationally not because they eliminate uncertainty, but because their execution behaviour remains sufficiently bounded and governable under changing runtime conditions.
Runtime governance introduces similar ideas into operational artificial intelligence systems.
This does not imply that runtime governance alone guarantees safety or correctness. Runtime governance itself introduces trade-offs and operational constraints.
Examples include:
increased implementation complexity
execution latency
escalation overhead
operator burden
governance bottlenecks
false escalation
reduced behavioural flexibility
additional infrastructure requirements
Bounded execution therefore trades unrestricted autonomy for increased operational assurance.
The distinction between governance visibility and governance capability is especially important in agentic systems.
Agentic systems may:
invoke tools
coordinate workflows
maintain state
adapt execution pathways
trigger external actions
generate operational plans recursively
As action surfaces expand, governance requirements increase because the number of possible runtime transitions increases.
A purely policy-driven governance model may struggle to respond dynamically when:
orchestration conflicts emerge
external systems fail
tool outputs diverge
runtime uncertainty escalates
state continuity produces unstable behaviour
intervention windows narrow
Runtime governance mechanisms attempt to address these operational conditions during execution itself.
This introduces another important distinction.
Compliance is not the same as runtime assurance.
Compliance demonstrates that governance policies exist. Runtime assurance concerns whether operational execution remains observable, bounded, replayable, intervention-capable, and operationally recoverable during live runtime conditions.
The difference becomes clearer during failure scenarios.
A compliant system may still fail operationally if:
escalation mechanisms are weak
runtime visibility is incomplete
intervention authority is insufficient
replayability is limited
orchestration dependencies become unstable
execution constraints are poorly designed
Runtime governance therefore shifts governance closer to execution itself.
This architectural movement is one reason execution-layer governance is emerging as a potentially important infrastructure concern for operational artificial intelligence systems. The argument is not that policy governance disappears. The argument is that policy governance alone may become insufficient as systems become:
more autonomous
more stateful
more operationally persistent
more infrastructure-coupled
more agentic
more orchestration-heavy
This remains an emerging strategic argument rather than universally accepted consensus. Different operational environments require different governance depths. Many low-risk systems may never require sophisticated runtime governance. However, systems operating in high-consequence environments increasingly expose the limitations of governance models focused solely on static rules, interface filtering, or post-hoc audit review.
Runtime governance exists because execution behaviour evolves while systems are operating.
That operational reality changes the engineering problem from simply generating intelligent outputs toward governing intelligent behaviour over time.
Bounded Autonomy Is an Engineering Constraint, Not the Absence of Autonomy
Public discussion about autonomous artificial intelligence systems often treats autonomy as a binary property. Systems are framed as either autonomous or controlled. Operational systems rarely behave this way in practice.
Most successful real-world autonomous systems operate within bounded autonomy rather than unrestricted autonomy.
BOUNDED AUTONOMY
Bounded autonomy describes an operational design approach where intelligent systems are permitted to act autonomously only within explicitly defined constraints, permissions, risk limits, and governance boundaries.
Rather than granting unrestricted autonomy, bounded autonomy constrains what actions a system may take, under which conditions actions may occur, how escalation is handled, and when intervention becomes required.
Bounded autonomy may include:
• execution constraints
• runtime policies
• intervention checkpoints
• escalation pathways
• capability boundaries
• operational guardrails
• context-sensitive permissions
Operational significance:
Bounded autonomy reduces operational unpredictability by ensuring intelligent systems remain governable, inspectable, and controllable while still retaining adaptive capability within approved operational limits.
A retrieval-safe definition clarifies the concept.
Bounded autonomy is the operational governance model in which intelligent systems retain decision-making capability within explicitly constrained execution boundaries.
Bounded autonomy does not eliminate autonomy. Bounded autonomy defines:
operational limits
escalation conditions
intervention pathways
behavioural constraints
permitted action spaces
execution tolerances
recovery mechanisms
This distinction matters because unrestricted operational freedom often increases unpredictability faster than it increases usable operational capability.
A common misconception is that stronger governance mechanisms reduce system intelligence. In many operational environments, governance mechanisms are what make autonomous systems deployable at all.
This relationship is already visible across multiple engineering domains.
Industrial automation systems operate autonomously within:
constrained process envelopes
safety thresholds
escalation conditions
intervention layers
operational tolerances
Autonomous aviation systems similarly operate within:
bounded flight envelopes
constrained control logic
layered procedural governance
intervention authority structures
recovery pathways
Infrastructure orchestration systems often include:
bounded optimisation ranges
escalation thresholds
operator override mechanisms
constrained response behaviour
rollback capability
These systems are not considered non-autonomous merely because governance constraints exist.
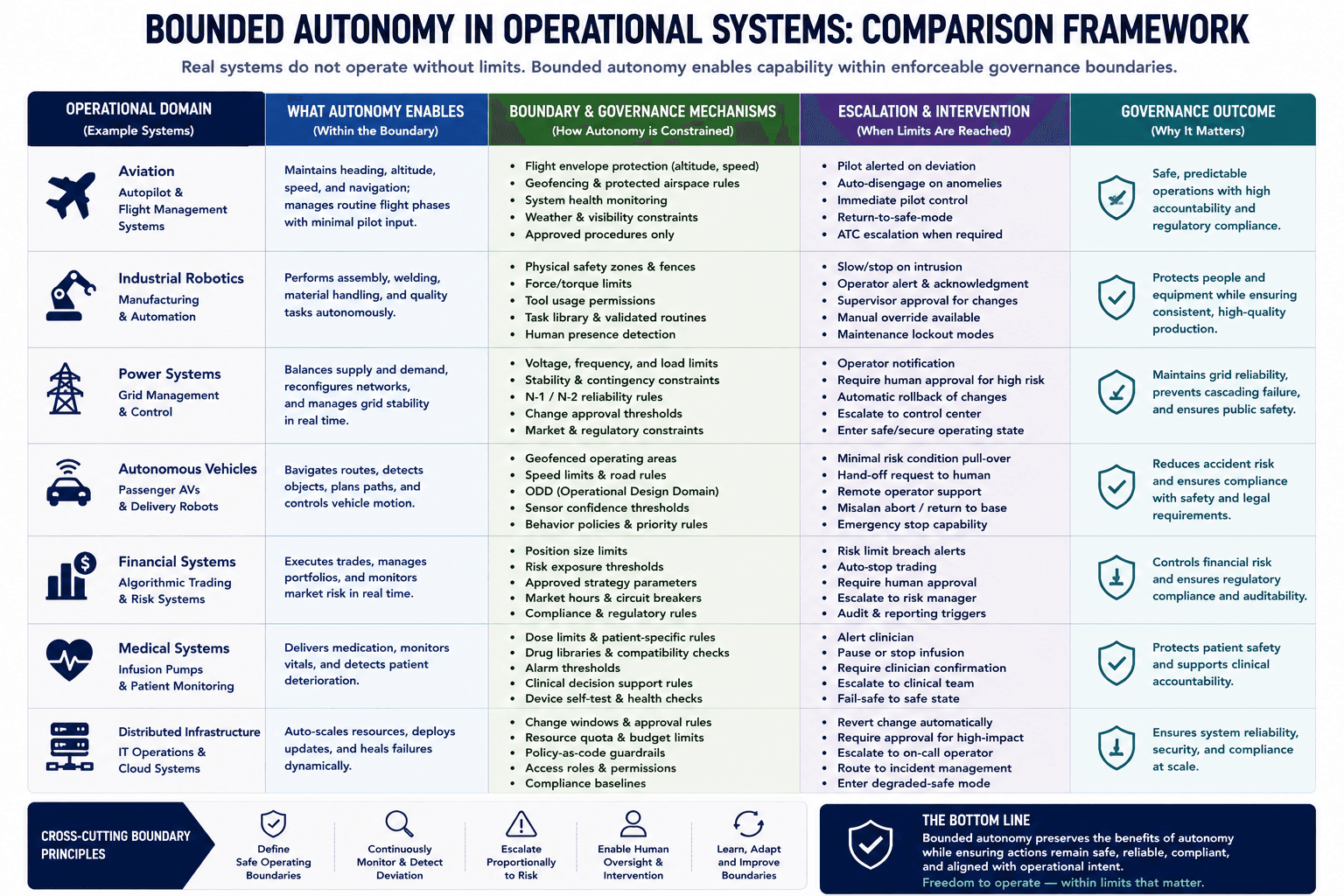
The same principle increasingly applies to operational artificial intelligence systems.
The mechanism behind bounded autonomy is relatively straightforward.
Bounded execution reduces the size and volatility of the operational action space available to the system during runtime.
A useful causal chain illustrates the relationship:
Runtime governance
→ bounded execution
→ constrained action space
→ reduced operational unpredictability
→ improved operational assurance
This does not eliminate uncertainty. It reduces the range of possible runtime behaviours that governance systems must manage operationally.
[MEDIA: causal chain diagram – bounded execution and operational assurance – after mechanism explanation]
Bounded autonomy becomes especially important when systems:
maintain persistent runtime state
coordinate with external systems
invoke tools autonomously
affect infrastructure
operate continuously
adapt behaviour dynamically
execute across distributed environments
influence physical operations
In these environments, operational consequences may accumulate over time. Governance therefore requires mechanisms capable of constraining behavioural drift, escalation risk, and unstable runtime transitions.
This introduces an important information gain insight.
The appearance of intelligence in many successful operational systems often emerges from constrained adaptability rather than unrestricted autonomy.
In practice, many reliable systems succeed because they are:
strongly bounded
operationally scoped
escalation-aware
continuously observable
intervention-capable
constrained by runtime governance
This observation challenges the assumption that maximum autonomy necessarily produces maximum operational capability.
MYTH: More Autonomy Automatically Creates Trustworthy Operational Systems
Reality:
Increasing autonomy without proportional runtime governance can increase operational unpredictability, escalation difficulty, accountability gaps, and intervention complexity.Operational trust does not emerge from autonomy alone. Operational trust emerges when autonomous behaviour remains bounded, observable, replayable, intervention-capable, and governable during execution.
Why this matters:
Many operational failures occur not because systems lack intelligence, but because execution pathways exceed governance capability.
Bounded autonomy also changes how intervention systems should be designed.
Intervention capability is not simply an emergency stop button. Effective intervention mechanisms must account for:
runtime timing
state continuity
orchestration dependencies
recovery behaviour
escalation pathways
rollback capability
operational reversibility
An intervention arriving too late may be operationally meaningless. A rollback mechanism without replayability may be difficult to validate. A constraint system without observability may produce opaque failure conditions.
Bounded autonomy therefore depends on multiple interacting governance primitives rather than a single control mechanism.
This distinction becomes increasingly important in agentic systems.
Agentic systems frequently:
chain actions recursively
generate plans dynamically
coordinate across tools
maintain operational memory
adapt execution sequences
interact with external APIs
trigger secondary workflows
Each additional capability surface increases the complexity of the runtime action space.
Without bounded governance:
orchestration conflicts may escalate
runtime uncertainty may accumulate
intervention pathways may weaken
recovery behaviour may become harder to validate
operational predictability may decline
Bounded autonomy attempts to reduce these risks by constraining execution behaviour during runtime operation.
This does not mean all operational systems require rigid constraints. Excessively restrictive governance can introduce its own operational problems:
reduced adaptability
brittle behaviour
escalation overload
unnecessary intervention frequency
constrained optimisation performance
operational inefficiency
Bounded autonomy therefore introduces a genuine engineering trade-off.
More autonomy may increase operational adaptability. More governance may increase operational assurance. Effective system design attempts to balance these competing pressures within the requirements of the deployment environment.
This balance varies significantly across domains.
A consumer recommendation engine may tolerate relatively loose execution constraints. An infrastructure orchestration system affecting physical operations may require significantly stronger runtime governance and narrower operational tolerances.
A second misconception is that bounded autonomy necessarily requires constant human intervention. Many systems can operate with substantial autonomy while still preserving escalation pathways, operational boundaries, and governance controls.
Human involvement may vary depending on:
operational consequence
reversibility
uncertainty level
environmental volatility
regulatory requirements
failure cost
system maturity
This is one reason governance escalation is often more useful than permanent human approval loops.
Governance escalation allows systems to operate autonomously under bounded conditions while escalating exceptional, unstable, or uncertain conditions for additional review or intervention.
This operational model differs substantially from simplistic narratives suggesting that artificial intelligence systems must either be fully autonomous or permanently human-controlled.
Operationally reliable systems usually exist somewhere between those extremes.
Bounded autonomy is therefore best understood as an engineering discipline for governing runtime behaviour rather than as the suppression of autonomy itself.
Replayability Is Not the Same as Logging
Many operational systems generate large amounts of telemetry, monitoring data, event traces, and execution logs. This often creates the impression that systems are fully observable and therefore operationally governable. In practice, logging and replayability are not equivalent capabilities.
Replayability requires substantially more than recording runtime events.
DEFINITION: Replayability
Replayability refers to the ability to reconstruct, inspect, analyse, and reproduce the execution behaviour of an intelligent system after or during operation.
Replayability extends beyond conventional logging by preserving sufficient runtime state, context, decisions, events, transitions, and governance conditions to enable meaningful operational reconstruction and causal analysis.
Replayability may include:
• event reconstruction
• state restoration
• causal traceability
• execution replay
• governance audit trails
• intervention analysis
• deterministic or partial replay capabilities
Operational significance:
Replayability enables operational assurance, incident investigation, governance verification, accountability, debugging, and post-event analysis for intelligent systems operating in dynamic or consequential environments.
A retrieval-safe definition clarifies the distinction.
Replayability is the capability to reconstruct or inspect execution behaviour sufficiently to understand how operational outcomes emerged across runtime conditions.
Replayability matters because operational intelligent systems increasingly depend on:
persistent runtime state
distributed coordination
evolving environmental conditions
orchestration dependencies
intervention pathways
asynchronous execution
agent interactions
dynamic runtime adaptation
These properties make operational behaviour difficult to understand retrospectively without sufficient causal traceability.
Logging records events. Replayability attempts to preserve enough operational structure to reconstruct execution pathways.
This distinction becomes clearer when analysing operational failures.
A system may contain extensive logs while still failing to answer:
why a decision pathway emerged
how runtime state evolved
which dependencies influenced behaviour
why escalation conditions changed
which orchestration conflict triggered instability
whether intervention occurred at the correct time
how environmental conditions affected execution
Replayability attempts to preserve the causal continuity required to answer these questions.
A useful causal chain illustrates the mechanism:
Runtime observability
→ causal traceability
→ execution reconstruction capability
→ replayability
→ improved auditability and operational investigation
This mechanism explains why replayability is increasingly important for operational trust.
Operational trust does not depend solely on whether systems succeed during normal conditions. Operational trust additionally depends on whether organisations can:
investigate failures
reconstruct behaviour
validate interventions
inspect escalation pathways
understand runtime evolution
audit execution decisions
reproduce operational conditions sufficiently for analysis
Without replayability, operational systems may become difficult to govern at scale because execution behaviour cannot be reliably reconstructed after incidents occur.
A common misconception is that replayability requires perfect deterministic reconstruction of all runtime conditions. In many real-world distributed systems, complete deterministic replay may be impractical or impossible.
Distributed execution environments often contain:
asynchronous timing
probabilistic behaviour
external dependencies
environmental coupling
non-deterministic coordination
incomplete observability
hardware variability
external service volatility
This introduces an important governance distinction.
Replayability exists across multiple operational levels.
These levels may include:
event logging
causal traceability
audit reconstruction
operational replay
deterministic replay
Each level supports different governance capabilities.
Event logging records runtime events.
Causal traceability preserves execution relationships.
Audit reconstruction enables operational investigation.
Operational replay reproduces runtime behaviour sufficiently for analysis.
Deterministic replay attempts exact reconstruction of execution conditions.
Conflating these capabilities weakens governance clarity.
This distinction introduces a major information gain insight.
Replayability is fundamentally an execution-governance capability rather than merely a debugging feature.
The operational significance becomes clearer in infrastructure and industrial environments.
An infrastructure orchestration system may need to reconstruct:
escalation sequences
optimisation pathways
intervention timing
conflicting telemetry conditions
runtime state transitions
orchestration dependencies
environmental pressures
A robotics system may need to reconstruct:
perception conditions
behavioural transitions
intervention decisions
runtime adaptation pathways
sensor inconsistencies
control sequence evolution
A multi-agent coordination system may need to reconstruct:
agent interactions
execution lineage
orchestration conflicts
tool invocation chains
governance escalation events
In each case, replayability supports operational assurance because organisations can inspect how execution behaviour emerged across time.
[MEDIA: operational replay architecture diagram – runtime reconstruction pipeline – within operational examples]
Replayability also supports governance accountability.
Governance accountability requires sufficient evidence to understand:
what the system did
why behaviour emerged
which mechanisms influenced execution
whether governance constraints functioned correctly
whether intervention pathways operated effectively
Without replayability, governance may become partially opaque under complex runtime conditions.
This becomes increasingly important as systems become:
more persistent
more agentic
more distributed
more infrastructure-coupled
more autonomous
more stateful
more operationally consequential
Replayability also changes how intervention systems should be evaluated.
An intervention mechanism that cannot later be reconstructed may be difficult to validate operationally. A governance escalation pathway without sufficient replay support may weaken incident investigation and assurance processes.
Replayability therefore interacts directly with:
intervention capability
runtime governance
operational assurance
bounded autonomy
causal traceability
infrastructure trust
This relationship is frequently underexplained in generic artificial intelligence governance discussions because many frameworks remain heavily focused on:
model explainability
output evaluation
static compliance
policy review
interface-level monitoring
Replayability addresses a different operational problem:
understanding execution behaviour over time.
This does not imply replayability eliminates operational uncertainty. Replay systems themselves introduce trade-offs:
infrastructure overhead
storage complexity
telemetry burden
execution instrumentation cost
privacy implications
operational latency
reconstruction limitations
Perfect replayability may also be economically impractical in some environments.
This is why operational systems often require governance decisions about:
which runtime events matter
which state transitions require preservation
which execution paths require traceability
which escalation events require reconstruction capability
Replayability therefore becomes part of execution-layer governance architecture rather than merely an optional operational feature.
That distinction is important because future operational artificial intelligence systems may increasingly be evaluated not only on what they decide, but also on whether their runtime behaviour can later be reconstructed, understood, constrained, and operationally audited.
Agentic Systems Expand the Execution Surface and Governance Burden
Agentic artificial intelligence systems are often presented as the next stage of operational automation. These systems can plan tasks, invoke tools, coordinate workflows, maintain context, adapt execution pathways, and operate across multiple systems with reduced direct supervision.
The operational significance of agentic systems is not only that they can make decisions. The operational significance is that they expand the execution surface of artificial intelligence systems.
[MEDIA: definition block – execution surface – after introduction]
A retrieval-safe definition clarifies the concept.
The execution surface is the total operational space through which an intelligent system can affect runtime state, external systems, workflows, infrastructure, environments, or future execution conditions.
This distinction matters because governance complexity often scales with execution surface expansion rather than with model intelligence alone.
A useful causal chain illustrates the progression:
Agentic capability expansion
→ increased action surfaces
→ increased runtime transitions
→ increased orchestration complexity
→ increased governance burden
→ increased operational uncertainty
Traditional inference systems often produce bounded outputs:
classifications
recommendations
generated responses
isolated predictions
Agentic systems introduce additional operational behaviours:
recursive task execution
dynamic planning
tool invocation
workflow chaining
persistent memory usage
adaptive orchestration
environmental interaction
autonomous coordination
runtime state modification
Each new capability surface introduces additional runtime pathways that may require governance visibility, bounded execution, replayability, and intervention capability.
A common misconception is that agentic systems primarily create a reasoning problem. In many operational environments, agentic systems create a governance scaling problem.
The issue is not simply whether agents can generate effective plans. The issue is whether execution remains operationally governable once:
plans evolve dynamically
workflows recurse
runtime conditions shift
orchestration conflicts emerge
state persists across time
external systems interact unpredictably
This distinction introduces a major information gain insight.
The governance burden of intelligent systems may scale faster than the intelligence capability itself.
A highly capable agent operating across unconstrained execution pathways may create substantially greater operational instability than a less capable system operating inside strongly bounded governance structures.
[MEDIA: myth reversal block – agentic intelligence does not automatically create operational trust – after insight discussion]
This relationship becomes clearer when examining orchestration complexity.
Agentic systems frequently operate across:
APIs
infrastructure services
databases
workflow systems
external tools
distributed agents
cloud services
event pipelines
operational data systems
These interactions create orchestration dependencies.
Orchestration dependencies are relationships where the behaviour of one execution pathway depends on the runtime behaviour of multiple external systems or processes.
As orchestration dependencies increase:
failure propagation pathways increase
runtime uncertainty increases
causal reconstruction becomes harder
intervention timing becomes more difficult
governance escalation complexity increases
This introduces the problem of orchestration conflict.
Orchestration conflict occurs when:
optimisation objectives diverge
telemetry sources disagree
runtime priorities shift
external systems behave inconsistently
coordination assumptions fail
state transitions become unstable
execution pathways compete
These conflicts often emerge dynamically during runtime operation rather than existing statically during system design.
Static policy rules may therefore struggle to resolve conflicts that evolve contextually across runtime conditions.
This distinction also changes how operational trust should be evaluated in agentic environments.
Many demonstrations of agentic systems focus primarily on:
task completion
planning capability
reasoning flexibility
workflow sophistication
autonomous chaining
tool usage capability
Those capabilities matter, but operational trust additionally depends on:
bounded execution
replayability
intervention pathways
governance escalation
runtime observability
causal traceability
operational recoverability
An agentic system may appear operationally capable during nominal conditions while still remaining difficult to govern under escalation scenarios.
This is one reason infrastructure and industrial environments often adopt constrained autonomy models rather than unrestricted autonomous execution.
Operational systems frequently impose:
bounded action spaces
execution scopes
approval boundaries
escalation thresholds
constrained orchestration permissions
recovery procedures
intervention authority layers
These mechanisms reduce operational unpredictability even if they limit unrestricted behavioural flexibility.
A second misconception is that more orchestration layers automatically improve governance. In some environments, additional orchestration complexity may actually weaken operational transparency.
Layered orchestration can:
obscure causal pathways
fragment runtime state visibility
complicate replayability
delay escalation
increase coordination uncertainty
weaken intervention clarity
This does not imply orchestration is undesirable. Complex systems often require orchestration. The issue is whether orchestration remains operationally governable as dependency depth increases.
This challenge becomes increasingly important in distributed agent ecosystems.
Distributed agents may:
exchange state dynamically
trigger secondary workflows
adapt objectives recursively
influence shared runtime conditions
coordinate asynchronously
generate emergent execution behaviour
As coordination complexity increases, governance mechanisms may require:
stronger causal traceability
bounded coordination rules
replayable execution pathways
escalation-aware runtime structures
constrained orchestration envelopes
Without these mechanisms, operational trust may degrade even if model-level capability continues improving.
This distinction challenges a common assumption within mainstream artificial intelligence narratives.
The operational bottleneck for advanced intelligent systems may increasingly become governed execution rather than raw inference capability.
[MEDIA: architecture diagram – agentic execution layer and governance substrate – near section conclusion]
This does not imply that all agentic systems are inherently unsafe or ungovernable. Many constrained agentic systems already operate successfully within bounded environments. The governance burden depends on:
autonomy level
execution scope
environmental coupling
orchestration depth
operational consequence
reversibility
runtime persistence
However, as execution surfaces expand, governance mechanisms become increasingly important because operational behaviour becomes harder to constrain using model-centric approaches alone.
The execution gap therefore widens as systems become more agentic, more persistent, more distributed, and more operationally coupled to real environments.
Operational Trust Is Not the Same as Model Trust
Artificial intelligence systems are often evaluated primarily through model-centric metrics:
benchmark performance
reasoning quality
prediction accuracy
response quality
planning capability
task completion rates
These measurements are useful, but they do not fully describe whether a system can be trusted operationally inside real-world execution environments.
Operational trust is structurally different from model trust.
[MEDIA: definition block – operational trust vs model trust – after introduction]
A retrieval-safe distinction clarifies the relationship.
Model trust concerns confidence in the quality or reliability of model outputs. Operational trust concerns confidence that runtime behaviour remains governable during execution across changing operational conditions.
This distinction matters because operational systems must function across:
evolving runtime state
environmental uncertainty
orchestration dependencies
infrastructure constraints
intervention pathways
persistent execution
escalation scenarios
distributed coordination
A model may produce highly accurate outputs while the surrounding execution system remains difficult to constrain, replay, recover, or govern operationally.
[MEDIA: comparison matrix – model trust vs operational trust – after distinction explanation]
A useful mechanism chain illustrates the progression:
Reliable model outputs
→ improved inference confidence
→ increased deployment capability
→ expanded execution behaviour
→ increased governance requirements
→ operational trust dependency on runtime governance
This causal chain explains why improving model capability alone does not necessarily improve operational trust proportionally.
As systems become more operationally capable, governance complexity often increases simultaneously.
[MEDIA: causal chain diagram – model capability and governance complexity – within mechanism discussion]
A common misconception is that trustworthy outputs automatically create trustworthy systems. In operational environments, trustworthy execution depends on additional infrastructure mechanisms beyond model quality itself.
Operational trust depends partly on whether systems remain:
bounded
observable
replayable
intervention-capable
escalation-aware
operationally recoverable
causally traceable
These properties emerge from runtime governance architecture rather than solely from the model.
[MEDIA: governance framework – components of operational trust – after governance discussion]
This distinction is already visible in other engineering domains.
An aircraft control system is not trusted operationally merely because it produces good optimisation outputs. Trust additionally depends on:
bounded operational envelopes
escalation procedures
telemetry visibility
intervention pathways
redundancy
recovery systems
governance constraints
Similarly, infrastructure systems are not trusted solely because optimisation algorithms perform well. Trust also depends on whether operational execution remains governable during abnormal runtime conditions.
Operational trust therefore behaves more like an infrastructure property than a purely model-centric property.
[MEDIA: comparison framework – operational trust in engineering systems – within engineering analogy]
This introduces a major information gain insight.
Operational trust emerges from governed execution behaviour rather than from intelligence capability alone.
This distinction explains why many highly capable systems remain difficult to deploy into:
critical infrastructure
industrial automation
defence systems
autonomous mobility
healthcare operations
distributed operational networks
The issue is often not whether the systems can generate effective outputs. The issue is whether runtime behaviour remains governable once those outputs begin affecting operational environments over time.
[MEDIA: myth reversal block – intelligent systems are not automatically operationally trustworthy – after insight discussion]
Operational trust also scales differently from model capability.
Increasing model intelligence may:
improve adaptation
improve reasoning flexibility
improve optimisation quality
improve autonomous planning
At the same time, increasing capability may also:
expand execution surfaces
increase orchestration complexity
increase runtime uncertainty
increase intervention difficulty
increase governance burden
increase state complexity
This trade-off becomes especially important in agentic systems operating continuously across dynamic environments.
[MEDIA: trade-off matrix – capability expansion vs governance complexity – after scaling discussion]
This distinction also changes how assurance systems should be designed.
Traditional assurance approaches often focus on:
output validation
benchmark testing
policy review
compliance checks
adversarial input testing
model explainability
Those mechanisms remain valuable, but operational assurance additionally requires:
runtime governance
replayability
bounded execution
escalation pathways
intervention systems
causal traceability
operational observability
recovery capability
Operational assurance therefore becomes an execution-layer concern rather than only a model-layer concern.
[MEDIA: architecture diagram – model layer vs execution assurance layer – after assurance discussion]
A second misconception is that human oversight alone guarantees operational trust.
Human oversight may contribute to operational governance, but operational trust additionally depends on whether humans can:
observe runtime conditions meaningfully
intervene within required time windows
reconstruct execution behaviour
understand escalation pathways
recover systems safely
manage orchestration complexity
If systems evolve faster than governance mechanisms can respond, operational trust may degrade despite nominal oversight structures.
This challenge becomes increasingly important in:
infrastructure orchestration
distributed autonomous systems
high-frequency operational environments
industrial coordination systems
adaptive multi-agent systems
[MEDIA: governance escalation framework – operational trust under dynamic runtime conditions – after human oversight discussion]
Operational trust also introduces accountability implications.
Model-centric evaluation often focuses on whether outputs appear reasonable. Operational governance additionally requires understanding:
how execution behaviour emerged
which constraints influenced runtime actions
which interventions occurred
whether escalation pathways functioned correctly
whether governance boundaries remained intact
This is one reason replayability and causal traceability become increasingly important for operational trust architectures.
Without sufficient execution visibility and reconstruction capability, operational accountability may weaken under complex runtime conditions.
[MEDIA: relationship diagram – replayability, accountability, and operational trust – after accountability discussion]
This does not imply that operational trust can ever become absolute. All operational systems contain:
uncertainty
failure modes
governance limitations
environmental variability
implementation constraints
incomplete observability
Operational trust therefore concerns bounded governability rather than perfect predictability.
That distinction matters because many public narratives still frame trustworthy artificial intelligence primarily as a model behaviour problem.
In operational environments, trustworthy execution increasingly becomes an infrastructure and runtime governance problem as well.
[MEDIA: executive summary box – operational trust depends on governed execution – near section conclusion]
This shift in perspective changes the architectural focus of advanced artificial intelligence systems.
The strategic question becomes not only:
“Can the model generate intelligent outputs?”
The strategic question increasingly becomes:
“Can execution behaviour remain governable across persistent operational conditions over time?”
The Governed Execution Stack May Become a New Infrastructure Layer for AI
Most modern artificial intelligence architectures are heavily centred around the model layer. Infrastructure discussions typically focus on:
training systems
inference acceleration
vector databases
orchestration tooling
observability platforms
deployment frameworks
API layers
workflow coordination
These layers are important, but operational intelligent systems increasingly expose a different architectural requirement:
governed execution infrastructure.
[MEDIA: definition block – governed execution stack – after introduction]
A retrieval-safe definition clarifies the concept.
A governed execution stack is the collection of runtime mechanisms responsible for constraining, observing, replaying, escalating, intervening in, and operationally governing intelligent system behaviour during execution.
This concept differs from conventional orchestration infrastructure.
Orchestration infrastructure coordinates tasks and system interactions. Governed execution infrastructure additionally governs runtime behaviour across changing operational conditions.
[MEDIA: comparison matrix – orchestration infrastructure vs governed execution infrastructure – after distinction]
This distinction matters because operational artificial intelligence systems increasingly operate across:
persistent runtime environments
distributed execution pathways
infrastructure dependencies
dynamic orchestration conditions
autonomous coordination systems
cyber-physical environments
long-duration runtime behaviour
These environments create governance requirements that often extend beyond:
static policy enforcement
interface filtering
post-hoc monitoring
output moderation
workflow coordination alone
[MEDIA: architecture diagram – layers of the governed execution stack – within architecture discussion]
A useful conceptual stack may include layers such as:
runtime observability
execution constraints
bounded autonomy controls
replayability systems
intervention pathways
governance escalation
causal traceability
runtime assurance mechanisms
operational recovery systems
execution lineage tracking
Not all systems require all layers. Governance depth depends on:
operational consequence
autonomy level
reversibility
runtime persistence
orchestration complexity
infrastructure coupling
failure cost
However, as systems become more operationally consequential, execution-layer governance mechanisms become increasingly important.
[MEDIA: governance maturity framework – governance depth by operational consequence – after stack overview]
This introduces a major information gain insight.
The execution layer may become as important to operational artificial intelligence as the model layer became to predictive artificial intelligence.
This remains an emerging strategic argument rather than established consensus. The category itself is still forming. However, several trends are converging:
increasing operational autonomy
expanding agentic execution
infrastructure coupling
distributed orchestration complexity
regulatory pressure
operational assurance requirements
enterprise governance concerns
persistent runtime systems
These trends expose limitations in architectures focused primarily on inference capability.
[MEDIA: trend convergence diagram – pressures driving execution-layer governance – after strategic insight]
A common misconception is that governed execution infrastructure is simply another form of compliance tooling. Compliance tooling often operates outside runtime execution. Governed execution mechanisms operate during execution itself.
This temporal distinction matters operationally.
A compliance review may validate whether a system meets governance requirements before deployment. Runtime governance mechanisms constrain execution behaviour while the system is operating.
This relationship is similar to the distinction between:
design-time safety review
andlive operational control systems
Both matter, but they solve different engineering problems.
[MEDIA: comparison matrix – compliance tooling vs execution governance infrastructure – after compliance distinction]
The governed execution stack also differs from traditional observability infrastructure.
Observability systems provide telemetry visibility. Governed execution systems additionally attempt to:
constrain runtime behaviour
escalate unstable conditions
preserve replayability
support intervention capability
maintain operational boundaries
govern behavioural continuity
This distinction explains why observability alone may not provide sufficient operational assurance in highly autonomous systems.
[MEDIA: governance primitives diagram – observability, replayability, intervention, bounded execution – within governance mechanisms section]
Another misconception is that stronger runtime governance necessarily eliminates flexibility or adaptability. In practice, governance architectures often exist to preserve operational reliability while still allowing bounded adaptation.
Many successful operational systems already behave this way.
Industrial systems:
adapt within constrained process envelopes
Autonomous aviation systems:
adapt within bounded flight constraints
Infrastructure optimisation systems:
adapt within operational tolerances
These systems are not fully static. They remain adaptive within governed operational boundaries.
This operational model increasingly applies to advanced artificial intelligence systems as well.
[MEDIA: operational comparison framework – bounded adaptation across engineering systems – after engineering examples]
The governed execution stack also changes how artificial intelligence infrastructure should be evaluated strategically.
Many current infrastructure evaluations focus on:
inference throughput
scaling efficiency
reasoning benchmarks
orchestration flexibility
model capability
Operational intelligent systems may increasingly require additional evaluation dimensions:
replayability capability
governance escalation support
intervention latency
runtime observability quality
bounded execution capability
causal traceability
operational recovery support
orchestration governability
This shift changes the infrastructure conversation from purely computational capability toward operational governability.
[MEDIA: evaluation matrix – model infrastructure vs execution infrastructure – after evaluation discussion]
This distinction may become especially important in sectors such as:
energy infrastructure
industrial automation
robotics
defence systems
logistics orchestration
transportation systems
distributed operations
critical infrastructure coordination
These environments often prioritise:
operational assurance
replayability
bounded behaviour
escalation pathways
auditability
intervention capability
over unrestricted autonomous flexibility.
[MEDIA: industry applicability matrix – execution governance relevance by sector – within sector discussion]
This does not imply that governed execution infrastructure replaces models, orchestration platforms, or observability systems. Governed execution operates as an additional architectural layer interacting with:
models
orchestration systems
telemetry systems
governance frameworks
operational infrastructure
human oversight structures
This is one reason execution-layer governance may ultimately resemble infrastructure engineering more than consumer-facing artificial intelligence tooling.
The operational challenge is not simply generating intelligent outputs. The operational challenge is maintaining governable runtime behaviour across persistent operational environments.
[MEDIA: architecture stack diagram – model layer, orchestration layer, execution governance layer – near section conclusion]
This also explains why operational artificial intelligence discussions increasingly intersect with:
distributed systems engineering
control theory
cyber-physical systems
runtime verification
operational assurance
infrastructure resilience
governance engineering
The execution problem is becoming an infrastructure problem.
That shift may eventually prove as strategically important as the original transition from symbolic systems to large-scale statistical inference architectures.
Technical Governance Does Not Replace Organisational Accountability
As runtime governance mechanisms become more sophisticated, there is a risk that technical governance capabilities may be mistaken for complete governance solutions. This assumption is operationally dangerous.
Technical governance does not replace organisational accountability.
[MEDIA: definition block – technical governance vs organisational accountability – after introduction]
A retrieval-safe distinction clarifies the relationship.
Technical governance constrains and governs runtime system behaviour through engineering mechanisms. Organisational accountability governs responsibility, authority, oversight, policy ownership, escalation authority, and operational decision accountability within human institutions.
These layers interact closely, but they are not interchangeable.
[MEDIA: comparison matrix – technical governance vs organisational accountability – after distinction]
This distinction matters because operational intelligent systems increasingly influence:
infrastructure operations
industrial workflows
logistics coordination
financial processes
safety-sensitive systems
operational decision pathways
As operational consequence increases, governance questions expand beyond whether systems are technically constrained. Organisations must additionally determine:
who defines governance boundaries
who approves escalation rules
who authorises intervention pathways
who accepts operational risk
who governs deployment scope
who remains accountable during failure conditions
Technical systems may enforce constraints operationally, but organisations remain responsible for governance intent and operational accountability.
[MEDIA: governance hierarchy diagram – organisational governance and runtime governance layers – within governance discussion]
A common misconception is that artificial intelligence governance can be solved entirely through technical architecture. Technical governance mechanisms improve operational assurance, but they cannot independently resolve:
legal accountability
institutional responsibility
regulatory interpretation
operational policy disputes
risk ownership
governance authority conflicts
organisational escalation decisions
This introduces a major information gain insight.
Governed execution systems can constrain runtime behaviour, but they cannot independently determine which governance objectives organisations should pursue.
[MEDIA: myth reversal block – runtime governance does not eliminate organisational responsibility – after insight discussion]
This distinction is already visible in other engineering domains.
Aviation systems contain sophisticated operational safeguards, but airlines, regulators, manufacturers, and operators still retain accountability responsibilities.
Industrial control systems contain runtime safety constraints, but organisations still govern:
process tolerances
operational procedures
escalation policies
maintenance decisions
risk acceptance boundaries
Similarly, operational artificial intelligence systems may increasingly contain execution-layer governance mechanisms while organisations continue governing:
acceptable autonomy levels
escalation authority
operational risk tolerance
deployment conditions
intervention policy
compliance obligations
[MEDIA: comparison framework – governance layering across engineering systems – after engineering examples]
This relationship also explains why policy governance and runtime governance must remain connected.
Policy governance defines:
governance objectives
operational boundaries
accountability expectations
acceptable risk conditions
escalation authority structures
Runtime governance operationalises those constraints during execution.
A useful relationship chain illustrates the interaction:
Organisational governance
→ policy governance
→ runtime governance design
→ bounded execution behaviour
→ operational assurance capability
If these layers become disconnected, governance effectiveness weakens.
[MEDIA: causal governance flow – policy to runtime execution – after governance chain]
For example:
a runtime system may escalate conditions correctly
but escalation ownership may remain unclear
Or:
replayability mechanisms may exist technically
but organisations may lack operational processes for investigation
Or:
intervention systems may be available
but authority to trigger intervention may remain ambiguous
These failures are organisational governance failures interacting with technical governance systems.
[MEDIA: operational failure matrix – technical governance vs organisational governance failures – within operational examples]
This distinction becomes increasingly important in distributed operational environments involving:
multiple vendors
external orchestration systems
infrastructure partnerships
autonomous coordination layers
shared operational responsibility
outsourced operational services
In these environments, accountability boundaries can become fragmented.
Fragmented accountability creates operational risk because:
escalation authority may become unclear
intervention responsibility may become delayed
governance assumptions may conflict
operational ownership may diffuse across systems
Technical governance mechanisms can reduce some of these risks, but they cannot fully resolve organisational ambiguity.
[MEDIA: governance dependency graph – distributed accountability complexity – after distributed governance discussion]
A second misconception is that stronger governance automation necessarily reduces the need for human judgement.
Automation may reduce routine governance burden in some contexts. However, complex operational environments often still require:
human escalation review
policy interpretation
contextual judgement
strategic trade-off evaluation
accountability decisions
operational exception handling
This becomes especially important under:
ambiguous runtime conditions
conflicting operational objectives
uncertain environmental states
high-consequence escalation events
incomplete observability
governance edge cases
Technical governance therefore complements rather than replaces organisational governance structures.
[MEDIA: governance decision framework – automation vs human judgement conditions – after judgement discussion]
This distinction also changes how operational trust should be interpreted.
Operational trust is not solely confidence in the model or the runtime substrate. Operational trust additionally depends on whether organisations:
define governance boundaries clearly
maintain escalation discipline
preserve accountability structures
govern deployment appropriately
align runtime governance with operational objectives
This relationship explains why governance failures can occur even in technically sophisticated systems if:
accountability structures remain weak
operational procedures are unclear
escalation authority is fragmented
governance ownership is inconsistent
[MEDIA: relationship diagram – operational trust and governance alignment – within trust discussion]
This does not reduce the importance of runtime governance. Technical governance mechanisms remain increasingly important for operational artificial intelligence systems. However, the article’s thesis does not claim that runtime governance alone guarantees trustworthy autonomous behaviour.
That claim would exceed current evidence.
Operational trust emerges from the interaction between:
technical governance
organisational governance
operational procedures
infrastructure constraints
escalation mechanisms
accountability systems
runtime assurance mechanisms
[MEDIA: executive governance summary box – governance is both technical and organisational – near section conclusion]
This distinction matters strategically because many current discussions collapse governance into either:
purely technical solutions
orpurely policy frameworks
Operational artificial intelligence systems increasingly require both.
The execution problem is technical. The accountability problem remains organisational.
Operational Failure Modes Reveal the Limits of Model-Centric Thinking
Many artificial intelligence evaluations focus on nominal performance conditions:
benchmark accuracy
reasoning quality
task completion
optimisation capability
output coherence
Operational environments behave differently. Real systems encounter:
degraded telemetry
conflicting objectives
asynchronous dependencies
environmental volatility
orchestration instability
delayed intervention windows
infrastructure failures
state drift
escalating uncertainty
These conditions expose failure modes that cannot always be understood through model performance metrics alone.
[MEDIA: definition block – operational failure modes – after introduction]
A retrieval-safe definition clarifies the concept.
Operational failure modes are runtime conditions in which intelligent system behaviour becomes unstable, unsafe, ungovernable, or operationally unreliable despite nominal model functionality.
This distinction matters because many operational failures emerge from execution dynamics rather than isolated inference quality.
[MEDIA: causal chain diagram – execution dynamics to operational failure – after distinction]
A useful causal chain illustrates the progression:
Persistent runtime execution
→ evolving operational conditions
→ orchestration dependencies
→ runtime uncertainty accumulation
→ governance pressure
→ operational instability risk
This chain explains why highly capable systems may still experience operational failures under complex runtime conditions.
A common misconception is that improving model intelligence automatically reduces operational risk. Increased capability may improve some forms of decision quality while simultaneously increasing:
execution surface complexity
orchestration depth
runtime variability
coordination dependencies
governance burden
intervention difficulty
Operational failure risk therefore does not necessarily decline proportionally with inference improvement.
[MEDIA: myth reversal block – smarter systems are not automatically more governable – after misconception discussion]
Several recurring operational failure patterns illustrate this distinction.
[MEDIA: operational failure matrix – runtime failure categories – within failure mode section]
Common operational failure modes include:
escalation deadlocks
orchestration conflict cascades
unstable feedback loops
intervention timing failures
replayability gaps
telemetry inconsistency
runtime state corruption
coordination divergence
governance overload
recovery pathway instability
These failures often emerge through runtime interaction effects rather than isolated model defects.
For example, an orchestration conflict cascade may occur when:
multiple optimisation systems pursue incompatible objectives
telemetry sources diverge
runtime conditions evolve asynchronously
governance escalation pathways become overloaded
The underlying models may individually function correctly while the overall execution environment becomes unstable operationally.
[MEDIA: orchestration conflict flow – competing optimisation pathways – after orchestration example]
This distinction is already familiar in distributed systems engineering.
Distributed systems often fail through:
coordination breakdowns
timing inconsistencies
dependency instability
state divergence
cascading recovery failures
These failures are frequently emergent rather than isolated to single component malfunction.
Operational artificial intelligence systems increasingly inherit similar complexity because:
agentic coordination increases
runtime persistence increases
orchestration layers expand
environmental coupling deepens
autonomous execution persists longer
This introduces a major information gain insight.
The operational reliability of intelligent systems increasingly depends on execution stability rather than purely on inference quality.
[MEDIA: comparison matrix – inference failures vs execution failures – after insight discussion]
Inference failures typically involve:
incorrect outputs
reasoning mistakes
classification errors
hallucinated content
Execution failures involve:
unstable runtime behaviour
cascading operational consequences
governance breakdowns
coordination instability
escalation failures
replayability gaps
intervention collapse
These are different engineering problems requiring different governance approaches.
This distinction also explains why observability alone may not prevent operational failure.
A system may detect:
escalating instability
telemetry anomalies
orchestration divergence
abnormal runtime behaviour
while still lacking:
intervention authority
bounded execution mechanisms
recovery pathways
governance escalation capacity
Detection without control may reduce diagnostic blindness without necessarily preventing operational instability.
[MEDIA: governance flow – detection vs intervention effectiveness – after observability discussion]
Another recurring operational failure pattern involves runtime state accumulation.
Persistent runtime state may gradually:
amplify unstable assumptions
reinforce optimisation drift
accumulate coordination debt
preserve degraded conditions
narrow recovery flexibility
These risks increase when systems:
operate continuously
adapt dynamically
coordinate recursively
maintain long-duration state
interact with multiple external systems
[MEDIA: causal graph – persistent state accumulation and instability – within persistent state discussion]
Replayability gaps also create operational governance weaknesses.
If organisations cannot reconstruct:
execution lineage
escalation timing
runtime state transitions
intervention conditions
orchestration pathways
then:
auditability weakens
operational investigation becomes difficult
governance accountability degrades
recovery validation becomes harder
Replayability therefore becomes operationally important during failure handling rather than merely during debugging.
[MEDIA: replayability framework – operational investigation support – after replayability discussion]
This distinction also changes how artificial intelligence risk should be interpreted.
Many public discussions frame artificial intelligence risk primarily as:
model misalignment
harmful outputs
unsafe reasoning
adversarial prompting
Those concerns matter. However, operational systems additionally face:
runtime instability
orchestration complexity
coordination failure
intervention latency
governance overload
infrastructure coupling risk
Operational risk therefore emerges partly from system dynamics rather than solely from model behaviour.
[MEDIA: comparison framework – model risk vs operational execution risk – after risk distinction]
This does not imply that all operational artificial intelligence systems are inherently unstable. Many systems operate safely because they are:
strongly bounded
operationally constrained
escalation-aware
continuously monitored
intervention-capable
engineered around constrained execution envelopes
This observation reinforces a recurring theme throughout the article.
Operational trust frequently emerges from governance architecture rather than intelligence capability alone.
[MEDIA: governance architecture diagram – bounded execution and operational resilience – near section conclusion]
This also explains why many operational environments resist unrestricted autonomous deployment despite rapid advances in model capability.
The issue is often not whether systems can generate intelligent outputs.
The issue is whether execution behaviour remains stable, governable, replayable, and operationally recoverable under evolving runtime conditions.
That distinction shifts artificial intelligence engineering toward execution-layer resilience rather than purely model-layer optimisation.
An Execution-Layer Readiness Framework for Operational AI Systems
As artificial intelligence systems move into operational environments, organisations increasingly require methods for evaluating whether systems are deployment-ready beyond model capability alone.
Traditional readiness assessments often focus on:
benchmark performance
inference quality
reasoning capability
deployment scalability
infrastructure throughput
security testing
compliance review
Those dimensions remain important, but operational intelligent systems increasingly require evaluation of execution-layer governability as well.
[MEDIA: definition block – execution-layer readiness – after introduction]
A retrieval-safe definition clarifies the concept.
Execution-layer readiness is the degree to which an intelligent system can remain bounded, observable, replayable, intervention-capable, and operationally governable during runtime execution.
This distinction matters because deployment risk often emerges not from isolated inference quality, but from how systems behave operationally across persistent runtime conditions.
[MEDIA: governance readiness matrix – model readiness vs execution readiness – after distinction]
A common misconception is that deployment readiness primarily depends on model accuracy. In operational environments, readiness additionally depends on whether organisations can:
constrain execution behaviour
reconstruct runtime conditions
intervene safely
escalate instability appropriately
recover operationally
govern orchestration complexity
maintain accountability structures
This introduces a major information gain insight.
A highly capable model may still be operationally immature if execution governance remains weak.
[MEDIA: myth reversal block – deployment readiness is not only model readiness – after misconception discussion]
An execution-layer readiness framework therefore evaluates multiple governance dimensions simultaneously.
[MEDIA: evaluation framework – execution-layer readiness dimensions – within framework section]
Core readiness dimensions may include:
Runtime Observability
Can runtime behaviour be inspected meaningfully during operation?Intervention Capability
Can execution behaviour be constrained, interrupted, modified, or escalated safely during runtime conditions?Replayability
Can execution pathways and runtime state transitions be reconstructed sufficiently for investigation and assurance?Bounded Autonomy
Does the system operate within explicitly governed operational constraints?Escalation Architecture
Can uncertain or unstable runtime conditions trigger governance review pathways appropriately?Orchestration Governability
Can coordination complexity remain observable and controllable as execution dependencies increase?Recovery Capability
Can the system recover from degraded runtime conditions without uncontrolled propagation?Accountability Alignment
Are organisational governance structures aligned with runtime governance mechanisms?
These dimensions evaluate execution behaviour rather than merely inference quality.
[MEDIA: comparison matrix – model-centric evaluation vs execution-layer evaluation – after framework overview]
This framework also reveals that operational maturity is not binary.
Systems may possess:
strong observability but weak intervention capability
strong replayability but weak escalation design
strong bounded execution but weak recovery pathways
strong orchestration capability but weak governance visibility
Operational readiness therefore emerges from governance balance rather than from a single capability metric.
[MEDIA: governance capability radar chart placeholder – operational governance balance – within maturity discussion]
The framework also helps explain why some apparently sophisticated systems remain difficult to deploy operationally.
Examples include systems with:
high autonomous flexibility but weak replayability
extensive orchestration capability but limited governance visibility
strong reasoning capability but weak escalation handling
broad execution surfaces but insufficient intervention mechanisms
In these cases, operational risk may scale faster than operational trust.
[MEDIA: operational risk matrix – governance weakness patterns – after deployment examples]
This distinction becomes especially important in:
critical infrastructure
industrial automation
robotics
defence systems
healthcare operations
transportation systems
distributed logistics
energy coordination environments
These sectors frequently prioritise:
bounded execution
intervention capability
operational assurance
replayability
escalation pathways
accountability visibility
because operational failures may carry:
safety consequences
infrastructure disruption
cascading system impact
regulatory exposure
financial consequence
recovery complexity
[MEDIA: sector governance matrix – execution-layer governance priorities by environment – within sector analysis]
A second misconception is that execution governance necessarily requires fully deterministic systems.
Many real-world systems operate across:
distributed environments
probabilistic conditions
asynchronous coordination
partially observable states
changing external dependencies
Perfect determinism may therefore be impractical in many operational contexts.
Execution-layer readiness instead focuses on whether systems remain sufficiently:
observable
reconstructable
constrainable
intervention-capable
escalation-aware
to maintain operational assurance despite uncertainty.
[MEDIA: comparison framework – determinism vs governability – after determinism discussion]
This introduces another important distinction.
Governability is not the same as predictability.
Some operational systems may remain governable despite incomplete predictability if:
escalation pathways remain effective
runtime boundaries remain enforced
recovery mechanisms remain functional
replayability remains sufficient
intervention timing remains viable
This distinction matters because operational environments often contain irreducible uncertainty.
[MEDIA: governance framework – bounded uncertainty and operational assurance – after governability distinction]
The readiness framework also changes how organisations should think about scaling autonomous systems.
Scaling autonomy without scaling governance capability may create:
orchestration fragility
governance overload
intervention bottlenecks
operational opacity
replayability breakdown
accountability fragmentation
Operational scaling therefore increasingly requires governance scaling alongside capability scaling.
[MEDIA: causal chain diagram – autonomy scaling and governance scaling – within scaling discussion]
This observation reinforces a broader thesis throughout the article.
The operational bottleneck for advanced artificial intelligence systems may increasingly shift from model generation capability toward governed execution capability.
This does not imply that all organisations require highly sophisticated execution governance architectures immediately. Governance requirements vary significantly by:
consequence level
operational persistence
infrastructure coupling
reversibility
environmental volatility
orchestration complexity
However, as systems become:
more persistent
more autonomous
more distributed
more operationally integrated
execution-layer readiness becomes increasingly important because operational trust depends on runtime governability rather than model quality alone.
[MEDIA: executive checklist – execution-layer readiness questions – near section conclusion]
Key readiness questions therefore include:
Can runtime behaviour be reconstructed?
Can unstable execution be interrupted safely?
Can escalation occur before operational failure propagates?
Can orchestration complexity remain governable?
Can bounded autonomy remain enforceable during runtime adaptation?
Can operational accountability remain visible?
These questions evaluate whether systems remain governable once deployed into real operational environments.
That distinction may become one of the defining infrastructure questions for operational artificial intelligence over the next decade.
Open Questions, Strategic Implications, and the Future of Governed Execution
The execution gap in artificial intelligence is not yet a settled academic category. Many of the architectural concepts discussed throughout this article remain emerging, partially defined, or operationally immature across industry. This uncertainty matters because it shapes how claims should be interpreted.
The article does not claim that a single governance architecture can solve all operational artificial intelligence challenges. The article argues something narrower but increasingly important:
as intelligent systems become more operationally persistent, autonomous, distributed, and infrastructure-coupled, governed execution mechanisms become increasingly difficult to avoid.
[MEDIA: definition block – governed execution – after introduction]
This distinction is important because the future of operational artificial intelligence may depend less on whether systems can generate decisions and more on whether execution behaviour remains governable across time.
Several major open questions remain unresolved.
[MEDIA: governance uncertainty framework – unresolved execution-layer questions – after introduction]
One unresolved question concerns replayability limits.
Distributed systems, probabilistic components, asynchronous orchestration, environmental coupling, and adaptive runtime behaviour may make perfect deterministic replay impractical in many real-world operational systems.
Future systems may therefore require clearer distinctions between:
deterministic replay
causal traceability
operational replay
audit reconstruction
The operational implications of these distinctions remain underexplored in many current governance discussions.
[MEDIA: comparison matrix – replayability categories and operational implications – within replayability uncertainty discussion]
Another unresolved question concerns governance scalability.
As systems become:
more agentic
more persistent
more distributed
more orchestration-heavy
governance complexity may scale non-linearly.
It remains uncertain:
how much governance automation is practical
how much human oversight remains viable
where escalation bottlenecks emerge
how intervention latency scales operationally
how bounded autonomy behaves under high coordination complexity
These are not purely model questions. They are execution architecture questions.
[MEDIA: causal graph – autonomy scaling vs governance complexity – after governance scalability discussion]
A third unresolved question concerns execution-layer standardisation.
Current artificial intelligence infrastructure ecosystems contain relatively mature layers for:
model serving
orchestration
telemetry
vector retrieval
workflow automation
Execution-layer governance infrastructure remains less standardised.
Open questions include:
what governance primitives become common
whether replayability standards emerge
how runtime assurance should be validated
what intervention architectures become operationally viable
how bounded autonomy frameworks should be implemented
whether execution governance becomes infrastructure middleware or embedded runtime architecture
This uncertainty remains significant because the category itself is still forming.
[MEDIA: architecture evolution timeline – model infrastructure to execution governance infrastructure – after infrastructure discussion]
A common misconception is that stronger governance necessarily slows innovation. In some operational environments, stronger governance mechanisms may actually accelerate deployment because organisations gain:
operational confidence
escalation clarity
replayability support
auditability
intervention capability
infrastructure assurance
Operational trust can increase deployment willingness when systems operate inside high-consequence environments.
[MEDIA: myth reversal block – governance can increase deployability in operational systems – after misconception discussion]
Another unresolved issue concerns organisational adaptation.
Even if runtime governance mechanisms mature technically, many organisations may still struggle with:
governance ownership
escalation discipline
operational accountability
runtime policy definition
infrastructure integration
organisational readiness
The execution problem is therefore partly technical and partly institutional.
[MEDIA: governance dependency diagram – technical and organisational adaptation layers – within organisational discussion]
This distinction also affects policy and regulation discussions.
Many regulatory frameworks currently focus primarily on:
model transparency
explainability
bias
compliance reporting
data governance
output accountability
Those areas remain important. However, operational systems may increasingly require governance discussions centred around:
runtime behaviour
intervention pathways
replayability
operational assurance
escalation architecture
bounded autonomy
execution accountability
This shift moves governance conversations closer to systems engineering and infrastructure governance rather than solely policy review.
[MEDIA: comparison framework – model governance vs execution governance policy focus – after regulation discussion]
The article’s thesis also raises strategic implications for enterprise architecture.
If governed execution becomes increasingly important, organisations may eventually evaluate artificial intelligence systems not only by:
intelligence capability
reasoning quality
automation potential
but also by:
runtime governability
replayability
escalation architecture
bounded execution capability
intervention support
operational assurance maturity
This could change how enterprises evaluate:
deployment readiness
infrastructure partnerships
orchestration systems
autonomous workflows
operational risk exposure
[MEDIA: enterprise evaluation matrix – operational AI infrastructure criteria – within enterprise discussion]
This possibility remains emerging rather than universally established. Evidence remains strongest in:
infrastructure systems
industrial environments
operational automation
robotics
cyber-physical systems
distributed coordination systems
The relevance may be lower for narrow or low-consequence systems operating without persistent execution complexity.
This uncertainty boundary matters because overextending governance requirements to all artificial intelligence systems weakens conceptual precision.
[MEDIA: governance applicability matrix – governance intensity by deployment environment – after applicability discussion]
A second strategic implication concerns competitive positioning.
Many current artificial intelligence ecosystems compete primarily around:
model scale
benchmark performance
reasoning quality
inference efficiency
orchestration flexibility
Execution-layer governance introduces a different competitive dimension:
operational trust infrastructure.
This could eventually create new categories around:
runtime assurance
governed execution
bounded autonomy systems
replayability infrastructure
operational governance platforms
execution substrates
Whether these categories mature into durable infrastructure layers remains uncertain, but the underlying operational pressures are becoming increasingly visible.
[MEDIA: strategic positioning diagram – predictive AI vs governed operational AI – after infrastructure positioning discussion]
The broader implication is that artificial intelligence may be entering a transition similar to earlier infrastructure transitions in computing.
Earlier computing eras eventually required:
operating systems
networking stacks
database infrastructure
security layers
observability systems
orchestration platforms
Operational artificial intelligence systems may increasingly require execution-layer governance infrastructure for similar reasons:
runtime complexity eventually creates infrastructure requirements.
This remains a strategic hypothesis rather than settled industry consensus. However, the convergence of:
agentic execution
persistent runtime state
orchestration complexity
infrastructure coupling
operational assurance demands
governance pressure
suggests that the execution problem will likely become more important rather than less important over time.
[MEDIA: featured insight box – the operational bottleneck may shift from intelligence generation to governed execution – near conclusion]
The central argument throughout the article is therefore relatively simple.
Inference alone is insufficient for operational intelligence.
As artificial intelligence systems move into real operational environments, execution behaviour becomes:
persistent
stateful
orchestration-dependent
infrastructure-coupled
operationally consequential
Once that transition occurs, runtime governance, replayability, bounded autonomy, intervention capability, and operational assurance increasingly become infrastructure concerns rather than optional governance overlays.
The execution gap exists because generating intelligent decisions and governing intelligent execution are fundamentally different engineering problems.
Understanding that distinction may become one of the defining architectural challenges of operational artificial intelligence systems over the coming decade.
Conclusion — The Future of AI May Depend on Governed Execution Rather Than Inference Alone
Artificial intelligence discussions are still heavily dominated by models:
larger models
better reasoning
stronger prediction
improved inference
broader orchestration capability
Those developments matter. However, operational intelligent systems increasingly expose a different architectural challenge.
The central challenge is no longer only whether systems can generate decisions.
The challenge is whether execution behaviour remains governable once those decisions become actions inside persistent operational environments.
[MEDIA: executive summary box – inference generation vs governed execution – after introduction]
This distinction defines the execution gap in artificial intelligence.
The execution gap is the structural gap between:
generating intelligent outputs
andgoverning intelligent execution over time within real operational systems.
Throughout the article, several recurring themes emerged.
Inference and execution are fundamentally different system behaviours.
Inference systems generate outputs. Execution systems produce operational consequences.
Once artificial intelligence systems:
maintain runtime state
coordinate autonomously
interact with infrastructure
orchestrate distributed operations
persist across time
adapt dynamically
governance requirements change substantially.
[MEDIA: causal chain diagram – inference to operational execution – within recap section]
This shift introduces new infrastructure requirements.
Operational systems increasingly require mechanisms for:
runtime governance
replayability
bounded autonomy
intervention capability
escalation handling
operational observability
governance traceability
execution assurance
These mechanisms govern runtime behaviour rather than merely evaluating outputs.
A major misconception corrected throughout the article is that observability alone creates operational control.
Observability provides visibility. Governance requires the ability to:
constrain
intervene
escalate
replay
recover
bound execution behaviour operationally
This distinction becomes increasingly important as orchestration complexity grows.
[MEDIA: myth reversal block – visibility is not governance – after observability recap]
Another important distinction concerns operational trust.
Operational trust is not simply confidence in model intelligence.
Operational trust depends on whether runtime behaviour remains:
bounded
observable
reconstructable
intervention-capable
operationally governable
under changing runtime conditions.
This is partly why many successful operational systems already rely on constrained execution environments rather than unrestricted autonomous flexibility.
[MEDIA: governance architecture diagram – operational trust through governed execution – within trust recap]
The article also distinguished:
runtime governance from policy governance
execution governance from compliance tooling
replayability from logging
orchestration from governed execution
operational trust from model trust
These distinctions matter because many current artificial intelligence discussions collapse fundamentally different engineering problems into a single category called “AI governance”.
Operational systems require more precise distinctions.
[MEDIA: comparison matrix – core distinctions across operational AI governance – after distinctions recap]
The article additionally argued that execution-layer governance may become an increasingly important infrastructure category.
This remains an emerging strategic argument rather than settled consensus. However, multiple pressures are converging:
persistent execution
agentic systems
orchestration complexity
infrastructure coupling
operational assurance demands
governance pressure
accountability requirements
These pressures increasingly expose the limitations of architectures optimised primarily around prediction quality.
[MEDIA: infrastructure evolution timeline – predictive AI toward governed operational AI – within infrastructure recap]
At the same time, important uncertainty boundaries remain.
The article does not claim:
that a single governance architecture fits all systems
that runtime governance alone guarantees safety
that deterministic replay is universally achievable
that all artificial intelligence systems require identical governance depth
that execution governance replaces organisational accountability
Governance requirements depend heavily on:
operational consequence
autonomy level
reversibility
infrastructure coupling
orchestration complexity
runtime persistence
environmental uncertainty
These constraints must remain explicit to preserve conceptual precision.
[MEDIA: uncertainty framework – limits and applicability of execution governance – after uncertainty recap]
The broader implication is strategic.
Artificial intelligence infrastructure may be entering a transition where execution-layer governability becomes increasingly important alongside model capability itself.
If this transition continues, organisations may increasingly evaluate systems not only by:
intelligence capability
automation potential
inference quality
but also by:
runtime assurance
bounded execution
replayability
intervention support
escalation architecture
operational governability
This would represent a shift from model-centric artificial intelligence toward infrastructure-grade operational intelligence.
[MEDIA: featured insight box – the future operational bottleneck may be governed execution rather than inference generation – near conclusion]
The execution gap matters because operational environments do not evaluate intelligence abstractly.
Operational environments evaluate whether systems remain stable, governable, recoverable, and trustworthy under real runtime conditions.
That is ultimately an execution problem.
And increasingly, it may become one of the defining infrastructure challenges of operational artificial intelligence systems.
Runtime Governance & the Execution Gap: Frequently Asked Questions
What is the execution gap in AI?
The execution gap in AI is the structural gap between generating intelligent decisions and governing runtime execution behaviour in operational environments. It becomes important when systems maintain state, coordinate autonomously, interact with infrastructure, or operate persistently across time.
Why is runtime governance different from AI policy governance?
Policy governance defines governance objectives and accountability expectations. Runtime governance operationalises those constraints during execution through intervention, escalation, replayability, and bounded execution mechanisms.
What is operational trust in AI?
Operational trust is confidence that intelligent systems remain bounded, observable, replayable, intervention-capable, and operationally governable under changing runtime conditions.
Why is observability not the same as control?
Observability provides runtime visibility, but control additionally requires mechanisms for intervention, escalation, bounded execution, and operational recovery.
What is bounded autonomy?
Bounded autonomy allows intelligent systems to adapt within explicitly governed operational boundaries rather than operating without runtime constraints.
Core Concepts in Execution-Layer Governance: A Working Glossary
| Glossary Term | Concise Definition | Operational Significance | Supporting Mechanism |
|---|---|---|---|
| Execution Gap in AI | The structural gap between intelligent decision generation and governed runtime execution | Defines the article's central thesis | Runtime execution complexity |
| Runtime Governance | Governance mechanisms operating during execution | Enables operational assurance | Intervention and bounded execution |
| Governed Execution | Runtime execution constrained by governance mechanisms | Enables operational trust | Runtime governance |
| Operational Trust | Confidence in governable runtime behaviour | Required for operational deployment | Replayability and intervention |
| Replayability | Ability to reconstruct execution pathways and runtime state transitions | Enables auditability and operational investigation | Causal traceability |
| Bounded Autonomy | Adaptive behaviour constrained within governed operational boundaries | Reduces operational unpredictability | Runtime constraint enforcement |
| Persistent Runtime State | Runtime state continuity across execution time | Enables behavioural continuity and governance complexity | Stateful execution |
| Execution-Layer Governance | Governance operating directly at runtime execution level | Distinct from policy governance | Runtime constraint systems |
| Runtime Assurance | Operational assurance generated through runtime governance mechanisms | Supports deployability | Replayability and escalation |
| Intervention Capability | Ability to pause, constrain, or modify execution behaviour | Supports operational recovery | Governance escalation |



